Slurm이란 무엇인가
슬럼(Slurm)은 HPC 클러스터에서 자원 할당 및 작업 스케줄링을 관리하는 대표적인 오픈소스 도구이다. Ubuntu 22.04에서 Slurm Workload Manager를 설치하고 구성하는 방법에 대해 단계별 자습서 형식으로 노트로 정리해보겠다.
1. Slurm이란 무엇인가?
- “Simple Linux Utility for Resource Management”의 약자로, 다수의 컴퓨팅 노드를 갖춘 클러스터 환경에서 작업을 제출, 관리, 모니터링할 수 있도록 해주는 분산 자원 스케줄러(distributed workload manager)
- HPC(High Performance Computing) 환경에서 주로 사용되며, 대규모 컴퓨팅 클러스터에서 사용자들이 작업(job)을 제출하고, 자원을 효율적으로 분배하도록 도와주는 소프트웨어
2. Slurm의 주요 역할
| 역할 | 설명 |
|---|---|
| 작업 스케줄링 | 사용자로부터 제출된 작업을 대기열에 넣고, 자원이 가능한 시점에 실행 |
| 자원 관리 | CPU, GPU, 메모리, 노드 등을 추적하고 할당 |
| 큐 관리 | 작업 우선순위, 사용량 제한, 사용자 그룹별 정책 적용 |
| 모니터링 | 작업 상태, 자원 사용 현황, 노드 상태 등을 실시간으로 추적 |
| 다양한 인터페이스 제공 | srun, sbatch, squeue, scancel 같은 명령어 제공 |
3. Slurm 아키텍처
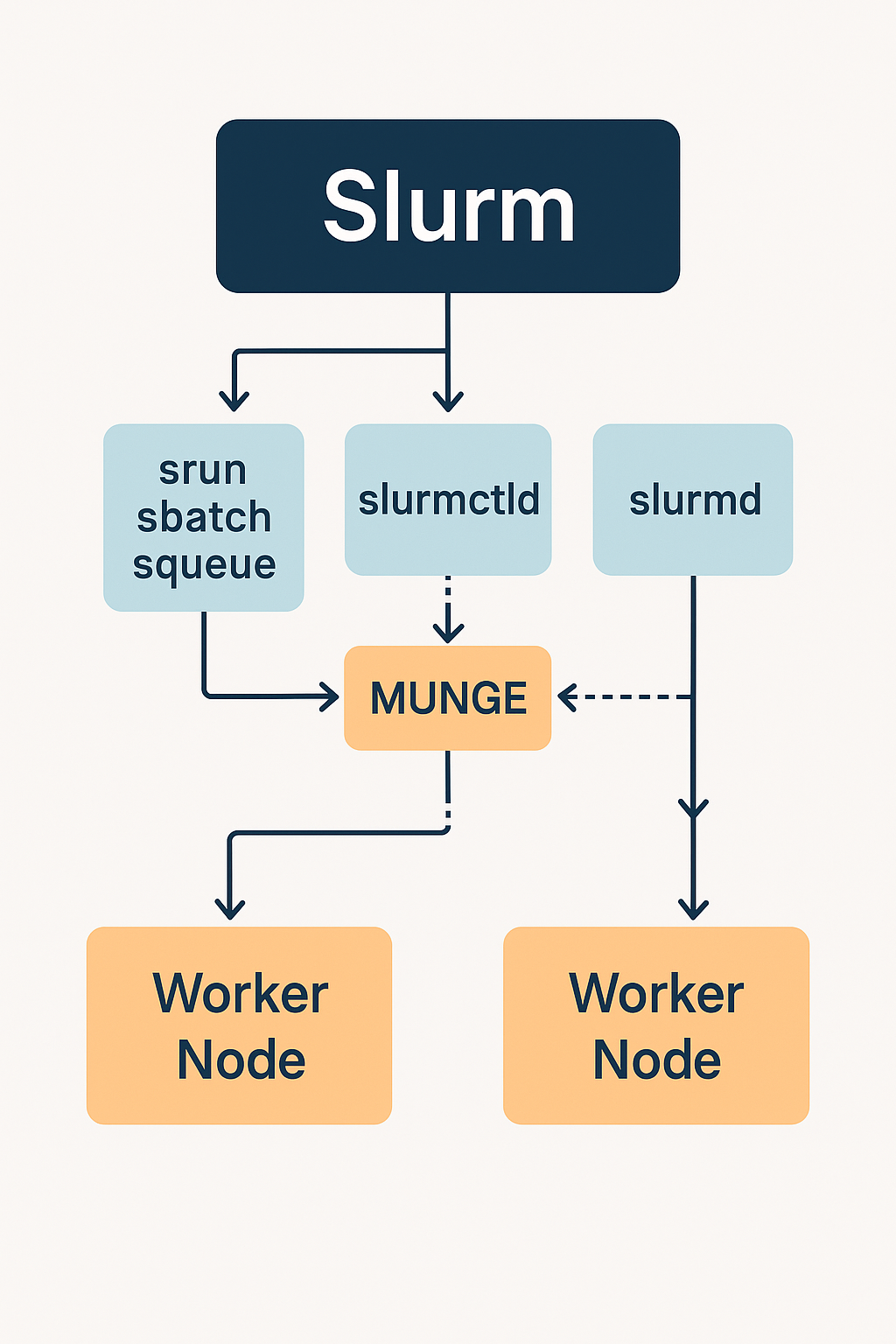
| 구성 요소 | 설명 |
|---|---|
slurmctld |
Slurm 컨트롤러 데몬. 클러스터의 중심에서 모든 작업을 관리 |
slurmd |
각 워커 노드에 설치되는 데몬. 작업 실행 및 상태 보고 |
slurmdbd (선택) |
Slurm accounting 데이터를 데이터베이스에 기록하는 데몬 |
munge |
보안 인증을 위한 토큰 기반 시스템 |
sinfo, squeue, sacct, scontrol 등 |
클러스터 상태 및 작업을 조회/관리하기 위한 유틸리티 도구 |
4. 장점
- 오픈 소스 및 활발한 커뮤니티 지원
- 수천 대 이상의 노드까지 확장 가능
- GPU, 메모리, CPU 등 다양한 자원 타입을 인식
- 다양한 스케줄링 정책 및 사용량 제한 기능
5. Slurm이 사용되는 곳
- 대학, 연구기관 HPC 센터
- 슈퍼컴퓨터 환경 (예: Oak Ridge의 Summit, NERSC의 Perlmutter 등)
- 기업 내 AI 연구 클러스터 (NVIDIA, Microsoft 등에서 사용)
- GPU 클러스터에서 대규모 AI 모델 학습 관리
댓글남기기