TensorRT와 TensorRT-LLM의 둘다 알아보기
어제 알아본 TensorRT와 TensorRT-LLM**은 **어떠한 차이점이 있을까? TensorRT는 모든 모델에 적용 가능한 범용 스포츠카 엔진이라면, TensorRT-LLM은 GPT·LLaMA만을 위한 F1 머신 엔진이라고 할 수 있다. Transformer 기반 LLM에 최적화된 기능과 성능을 원한다면 TensorRT-LLM이 압도적이다.
둘 다 NVIDIA에서 만든 딥러닝 추론 최적화 엔진이지만, 용도와 최적화 대상이 다르다. 이번에는 TensorRT 와 TensorRT-LLM의 차이에 대해 알아보고, TensorRT-LLM에 대해 좀 더 상세히 알아보자!
1. TensorRT-LLM이란?
- NVIDIA가 개발한 초거대 언어 모델(LLM) 추론을 위한 전용 추론 프레임워크
- 기존 TensorRT 위에 구축되어 있으며, 특히 LLaMA, GPT, Mistral, DeepSeek 등 대규모 Transformer 기반 모델의 빠른 추론을 위해 설계되었음
- 규모 언어 모델(LLM)의 추론 속도를 극대화하기 위한 NVIDIA의 GPU 최적화 추론 프레임워크
2. TensorRT-LLM 주요 특징
| 기능 | 설명 |
|---|---|
| FP8 / FP16 지원 | 최신 Hopper/H100 아키텍처에서 초고속 추론 성능 |
| KV 캐시 최적화 | FlashAttention + PagedAttention → 긴 문맥도 빠르게 처리 |
| Multi-GPU 지원 | 텐서 병렬(Tensor Parallel), 파이프라인 병렬, Multi-Node 지원 |
| 지원 모델 | LLaMA 2/3, GPT-J/NeoX, Mistral, DeepSeek, ChatGLM, Baichuan 등 |
| ONNX 불필요 | Transformer 구조에 최적화된 직접 변환 API 제공 |
| vLLM 대비 장점 | GPU 전용 환경에서 최대 속도 및 메모리 효율성 확보 가능 |
3. TensorRT-LLM 아키텍처
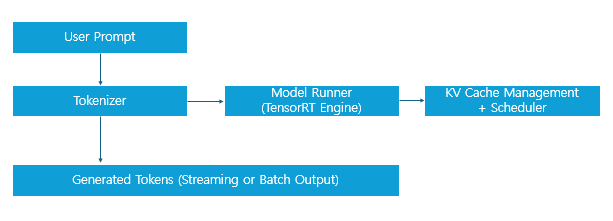
ModelRunner: TensorRT plan 파일 로딩 및 실행Scheduler: 멀티 스트림/배치 구성KV 캐시: Attention 속도 최적화를 위한 핵심 기술
4. 추론 성능 (vs PyTorch)
| 항목 | PyTorch | TensorRT-LLM |
|---|---|---|
| Throughput | 1x | 최대 8~15x ↑ |
| Latency | 기준 | 최대 60~80% ↓ |
| GPU 메모리 사용 | 높음 | 효율적 (Paged KV Cache 등) |
- LLM inference latency가 중요한 서비스형 AI(예: RAG, chatbot, agent)에 유리함
5. TensorRT vs TensorRT-LLM
| 항목 | TensorRT | TensorRT-LLM |
|---|---|---|
| 개발 목적 | CNN, DNN, 일반 모델 추론 최적화 | GPT, LLaMA 등 초거대 언어 모델 추론 최적화 |
| 지원 모델 | 이미지 분류, 객체 탐지, 음성 등 일반 모델 | LLaMA, GPT, Mistral, DeepSeek 등 Transformer 기반 LLM |
| 입력 포맷 | ONNX, TensorFlow, PyTorch (ONNX 주력) | HuggingFace 모델 직접 지원 (ONNX 불필요) |
| 최적화 기술 | Layer fusion, quantization, kernel tuning | KV 캐시, PagedAttention, FP8, 텐서 병렬 등 LLM 특화 |
| 병렬화 | 일반적으로 단일 GPU 중심 | Multi-GPU 텐서 병렬, 파이프라인 병렬, 노드 간 분산 지원 |
| 사용 방식 | ONNX → TensorRT 엔진으로 변환 후 실행 | HF 모델 → TensorRT-LLM 형식 변환 → 추론 |
| 추론 속도 향상 | 2~6배 (기존 프레임워크 대비) | 최대 10~20배↑ (PyTorch 대비, H100 기준) |
| 대상 사용자 | 범용 딥러닝 개발자 | 초거대 언어 모델 추론 엔지니어, 서비스 개발자 |
| 대표 유즈케이스 | 이미지/음성 추론, 로봇 비전 | AI 챗봇, RAG, 검색형 AI, Agent 서비스 |
6. TensorRT vs TensorRT-LLM 사용 예
| 상황 | 권장 |
|---|---|
| ResNet, YOLO, UNet 추론 | TensorRT |
| LLaMA 2/3, GPT 추론 | TensorRT-LLM |
| ONNX로 내보낸 작은 모델 | TensorRT |
| HuggingFace 모델 기반 실시간 챗봇 | TensorRT-LLM |
7. TensorRT-LLM 요약
| 항목 | 설명 |
|---|---|
| 목적 | LLM 추론 성능 최적화 (특히 H100 환경) |
| 핵심 기술 | FP8/FP16, KV 캐시, Multi-GPU 병렬화 |
| 지원 모델 | HuggingFace 기반 거의 모든 LLM |
| 사용 대상 | 실시간 대화형 AI, 검색형 AI, 추론 최적화 서비스 |
8. 공식 자료
-
블로그: https://developer.nvidia.com/blog/tensorrt-llm-supercharging-large-language-models-inference/
-
유투브: https://youtu.be/hhhvZdkxsCE
댓글남기기