NVIDIA Base Command Platform (BCP)는 NVIDIA가 제공하는 클라우드 기반의 AI 인프라 운영 및 워크로드 관리 플랫폼이다. DGX POD, DGX SuperPOD, 또는 기타 GPU 클러스터를 다중 사용자 환경에서 효율적으로 운영하고, 모델 훈련 워크플로우를 자동화할 수 있도록 설계되었다.
그러므로 Base Command Platform은 DGX 인프라를 위한 SaaS 형태의 통합 관리 포털로,
AI 워크로드 스케줄링, 실험 관리, 데이터셋 추적, GPU 모니터링 등을 웹 기반으로 제공한다. 자! 그렇다면, 좀더 상세히 알아 보도록 하자!
1. 주요 기능
기능
설명
웹 기반 UI
실험 실행, 리소스 상태 확인, 사용량 분석 가능
워크로드 스케줄링
Slurm 기반 훈련/추론 job 제출 및 모니터링
데이터/모델 버전 관리
데이터셋, 체크포인트, 결과물에 대한 버전 기록
다중 사용자 지원
사용자별 프로젝트, 권한, 할당량 관리
NGC 연동
PyTorch, TensorFlow, Triton 등 NVIDIA NGC 컨테이너 바로 실행 가능
통합 모니터링
GPU 사용률, 노드 상태, job 로그 실시간 확인
API & CLI 지원
자동화 및 외부 MLOps 도구 연동 가능
엔터프라이즈 통합
LDAP/SSO, 프록시, 프라이빗 NGC 등 기업용 환경 지원
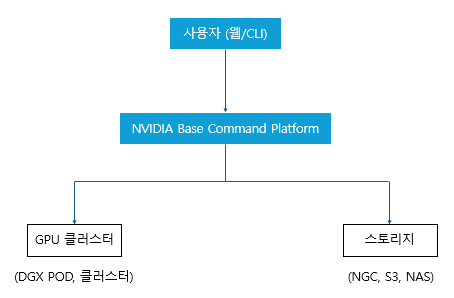
2. 아키텍처
[그림 - DGX POD 아키텍처]
3. 클라우드/SaaS 형태
NVIDIA가 직접 운영하는 클라우드 인프라에서 실행
고객은 웹 포털 접속만으로 DGX 인프라 사용 가능
데이터센터에 있는 DGX POD와 하이브리드 연동도 가능
Base Command Manager(온프레미스)와 연계되어 작동
4. 왜 필요한가?
필요 이유
설명
LLM 훈련
수십~수백 개 GPU에서 실험/모델 버전 관리가 복잡함 → 자동화 필요
여러 사용자 공유 환경
DGX POD를 여러 팀이 사용할 때 권한, 할당량 관리 필요
실험 추적성
어떤 모델/데이터셋/하이퍼파라미터로 어떤 결과가 나왔는지 쉽게 관리
엔터프라이즈 운영
대규모 GPU 인프라 운영을 위한 통합 대시보드 제공
5. 구성 비교: BCM vs BCP
항목
Base Command Manager (BCM)
Base Command Platform (BCP)
설치 위치
DGX 서버 내 로컬 설치
NVIDIA 클라우드 SaaS
대상
단일 노드 또는 소규모 클러스터
대규모 DGX POD, 엔터프라이즈
주요 기능
CLI 중심, Slurm job 관리
Web UI, 실험 관리, 사용자 할당
구매 방식
기본 포함 (무료)
별도 계약 및 유료
연동
Slurm, Kubernetes, NGC
LDAP, API, NGC Private Registry 등
6. 기본 제공과 옵션 차이
항목
DGX 시스템(단일)
DGX POD
DGX SuperPOD
Base Command Manager (BCM)
✅ 포함 (로컬 클러스터 관리)
✅ 포함
✅ 포함
Base Command Platform (BCP)
❌ 포함되지 않음 (클라우드 기반, 별도 구매)
❌ 기본 미포함, 옵션
❌ 기본 미포함, 옵션
7. Base Command 구성 요약
Base Command Manager (BCM) – ✅ 대부분 기본 포함
로컬 DGX POD/서버에서 운영되는 온프레미스 클러스터 관리 도구
Slurm 연동, GPU 사용 모니터링, 사용자 워크로드 스케줄링 등
기본적으로는 단일 DGX 또는 작은 POD 규모에서 제공됨
Base Command Platform (BCP) – ❌ 별도 구매 필요
클라우드 기반 통합 관리 플랫폼
기능
사용자 포털 제공 (Jupyter, 실험 트래킹, job 제출 UI)
다양한 DGX POD를 통합 관리
NGC 인증 모델 훈련 파이프라인 통합
다중 사용자 접근 제어 및 통계
SaaS 형태로 제공되며, 기업 단위 DGX POD 사용 시 유용
NVIDIA와 직접 계약이 필요함
예
설명
단일 DGX A100 서버
BCM만 포함. 커맨드라인 기반
사내 DGX POD (8~16 노드)
BCM은 기본, BCP는 필요 시 추가
엔터프라이즈 규모 DGX SuperPOD
BCM + BCP 도입 권장 (고객 요구에 따라 커스터마이징)
8. 사용 사례
조직
활용 목적
OpenAI, Meta
대규모 모델 훈련 파이프라인 자동화
NVIDIA 사내 AI팀
DGX SuperPOD 모니터링 및 운영
국가 연구소/대기업
GPU 인프라를 여러 프로젝트 팀이 공동 사용 시
9. 참고
NVIDIA는 NGC Private Registry, Model Registry, Base Command Platform을 연계하여 AI 워크플로우 전체를 관리하도록 유도함
하지만 많은 고객들은 DGX POD만 구매하고, 운영은 Slurm 또는 Kubernetes 등으로 자체 구성하는 경우가 많음
댓글남기기