가속 컴퓨팅과 NVLink의 관계
가속 컴퓨팅을 위한 인터커넥트의 금본위 기준은 바로 NVLink 이다. GPU와 CPU는 그 여정 중간에 위치한 자원들이며, 이들로 향하는 진입로는 고속 인터커넥트를 NVLink라고 부르는 데, 가속 컴퓨팅(Accelerated Computing)이란, 전통적인 CPU 중심의 컴퓨팅 방식을 넘어, GPU, FPGA, DPU 등 특수 하드웨어를 활용해 계산 속도와 효율을 획기적으로 높이는 기술이다.
CPU는 범용 계산에 강하지만, 병렬 연산이나 대규모 데이터 처리에서는 한계가 있다. 이때, 특정 연산에 특화된 프로세서를 함께 사용하면 전체 계산 속도를 가속할 수 있다. 그렇다면, 가속 컴퓨팅에서의 NVLInk에서 기술적인 관점으로 좀 더 알아보자!
1. 가속 컴퓨팅의 핵심 구성 요소
| 구성 요소 | 역할 |
|---|---|
| GPU (Graphics Processing Unit) | 대규모 행렬 계산, 병렬 연산에 최적. AI/딥러닝, 그래픽, HPC에 주로 사용 |
| DPU (Data Processing Unit) | 네트워크, 보안, 스토리지 오프로드 처리. 데이터센터의 인프라 가속 |
| FPGA (Field-Programmable Gate Array) | 사용자가 설계 가능. 지연시간이 매우 낮아 실시간 처리에 적합 |
| 고속 인터커넥트 (NVLink, PCIe 등) | GPU ↔ GPU, CPU ↔ GPU 간 빠른 데이터 전송 |
2. NVLink 내부 원리
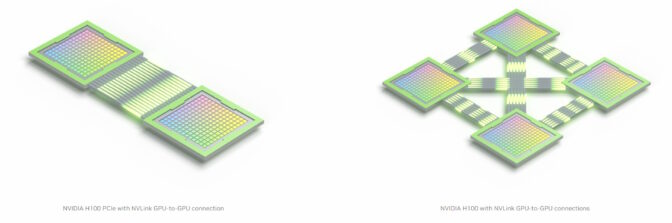
- NVLink는 GPU와 CPU 간의 고속 연결을 위한 기술로, 강력한 소프트웨어 프로토콜에 의해 형성되며 일반적으로 컴퓨터 보드에 인쇄된 여러 쌍의 와이어 위에서 동작함.
- 이 기술을 통해 프로세서들은 공유 메모리 풀로부터 데이터를 매우 빠른 속도로 송수신할 수 있음
- 현재 4세대까지 발전한 NVLink는 호스트 프로세서와 가속기 프로세서를 최대 초당 900기가바이트(GB/s) 속도로 연결함.
- 기존 x86 서버에서 사용되는 PCIe Gen 5 대비 7배 이상 높은 대역폭
- 데이터 전송 시 비트당 1.3피코줄(pJ) 만을 소비하여, 에너지 효율은 PCIe Gen 5보다 5배 뛰어남
3. NVLink 역사
-
처음에는 NVIDIA P100 GPU와 함께 GPU 간 인터커넥트로 도입되었음
-
2018년, NVLink는 GPU와 CPU를 연결하는 기술로 주목을 받으며, 세계에서 가장 강력한 슈퍼컴퓨터 중 두 대인 Summit과 Sierra에 적용되면서 고성능 컴퓨팅 분야에서 큰 주목을 받았음

- Summit 슈퍼컴퓨터: 미국 오크리지 국립연구소(Oak Ridge National Laboratory, ORNL)에 설치된 세계 최고 수준의 고성능 슈퍼컴퓨터로, NVIDIA GPU와 IBM POWER9 CPU를 결합한 이기종(Heterogeneous) 아키텍처를 특징으로 함.
- Sierra 슈퍼컴퓨터: 미국 로렌스 리버모어 국립연구소(Lawrence Livermore National Laboratory, LLNL)에 설치된 고성능 슈퍼컴퓨터로, 핵무기 안전성 시뮬레이션과 국가 안보 목적의 과학 연구를 위해 구축되었음. IBM POWER9 CPU와 NVIDIA Tesla V100 GPU, 그리고 NVLink 고속 인터커넥트를 사용하는 이기종(Heterogeneous) 구조
-
2020년, 3세대 NVLink는 GPU당 최대 대역폭을 600GB/s로 두 배 증가시켰음. NVIDIA A100 Tensor Core GPU에 12개의 NVLink 인터커넥트를 탑재함.
- A100은 전 세계의 엔터프라이즈 데이터센터, 클라우드 컴퓨팅 서비스, 고성능 컴퓨팅(HPC) 연구소 등에서 AI 슈퍼컴퓨터의 핵심 엔진으로 사용되고 있음.
-
현재의 4세대 NVLink는 하나의 NVIDIA H100 Tensor Core GPU에 총 18개의 NVLink 인터커넥트를 내장하고 있음
- 세계에서 가장 진보된 CPU 및 가속기 간의 전략적 연결을 위한 핵심 역할
4. Chip-to-Chip 링크: NVLink-C2C
-
NVIDIA NVLink-C2C는 기존 보드 간 NVLink에서 확장된 형태로, 하나의 패키지 내부에서 두 개의 프로세서를 직접 연결하는 초고속 칩 간 인터커넥트

- Grace CPU 슈퍼칩:
- NVLink-C2C를 통해 두 개의 CPU 칩을 연결하여 총 144개의 Arm Neoverse V2 코어를 제공함.
- 클라우드, 엔터프라이즈, HPC 사용자들을 위한 에너지 효율적인 성능을 제공함.
- Grace Hopper 슈퍼칩:
- Grace CPU와 Hopper GPU를 NVLink-C2C로 연결하여, 가속 컴퓨팅 성능을 단일 칩에 통합해, AI 및 HPC 분야의 가장 복잡한 작업을 처리할 수 있음
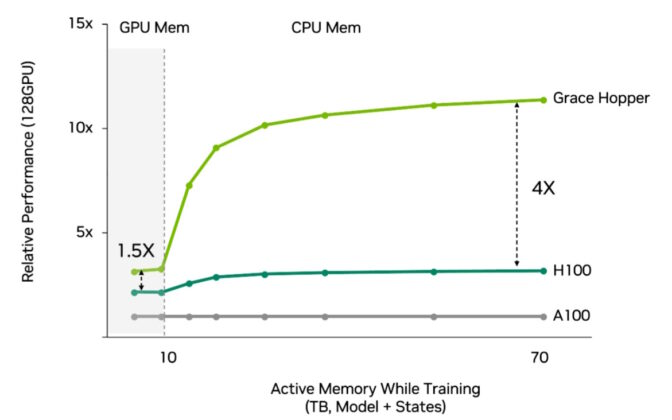
- 실제 적용 사례: 스위스의 AI 슈퍼컴퓨터 - Alps
- Alps는 스위스 국가 슈퍼컴퓨팅 센터(CSCS)에서 구축 중인 AI 슈퍼컴퓨터
- Grace Hopper 슈퍼칩을 사용하는 세계 최초의 시스템 중 하나가 될 예정
- 천체물리학에서 양자화학에 이르기까지 다양한 과학 분야의 거대한 문제를 해결하는 데 사용
4. NVLINK - LEGO 블록의 연결 소켓
-
NVLINK는 가장 큰 HPC 및 AI 작업을 처리하기 위한 슈퍼시스템을 구성하는 기반 기술
-
NVIDIA DGX 시스템의 8개 GPU는 NVLink와 NVSwitch 칩을 통해 고속의 직접 연결을 공유 -> 서버 내 모든 GPU가 하나의 통합된 시스템으로 동작하는 NVLink 네트워크가 구성됨
-
더 높은 성능을 얻기 위해, DGX 시스템 여러 대를 최대 32개까지 모듈형 유닛으로 스택(Stack) 하면, 강력하고 효율적인 컴퓨팅 클러스터를 만들 수 있음

-
사용자는 32대의 DGX 시스템을 하나의 AI 슈퍼컴퓨터로 통합함
- DGX 내부는 NVLink 네트워크, 시스템 간 연결은 NVIDIA Quantum-2 스위치를 활용한 InfiniBand 패브릭으로 구성
- NVIDIA DGX H100 SuperPOD는 256개의 H100 GPU를 탑재하여 최대 1 엑사플롭(Exaflop)의 AI 연산 성능을 제공함
-
더 높은 성능이 필요한 경우, 사용자는 클라우드 기반 AI 슈퍼컴퓨터를 활용
-
Microsoft Azure는 수만 개의 A100 및 H100 GPU로 구성된 인프라를 구축 중
-
이 서비스는 OpenAI와 같은 기관이 세계 최대 규모의 생성형 AI 모델을 훈련하는 데 사용됨
-
- Grace CPU 슈퍼칩:
댓글남기기