더 똑똑하고 강력한 AI를 만드는 스케일 법칙
스케일링 법칙은 AI 시스템의 성능이 훈련 데이터의 양, 모델 파라미터 수, 또는 계산 자원의 크기가 증가함에 따라 어떻게 향상되는지를 보여 준다. 그동안 더 많은 연산 자원, 더 많은 훈련 데이터, 더 많은 파라미터가 더 나은 AI 모델을 만든다는 것이 스케일링 법칙의 정설이었다.
그러나 최근의 인공지능은 예전과 달리 훨씬 더 복잡해져, 연산 자원을 어떻게 활용 하느냐에 따라 모델 성능이 어떻게 달라지는지를 깨닫게 되었다. 그래서 오늘은 그러한 AI 스케일링의 세 가지 법칙에 대해 알아보자.
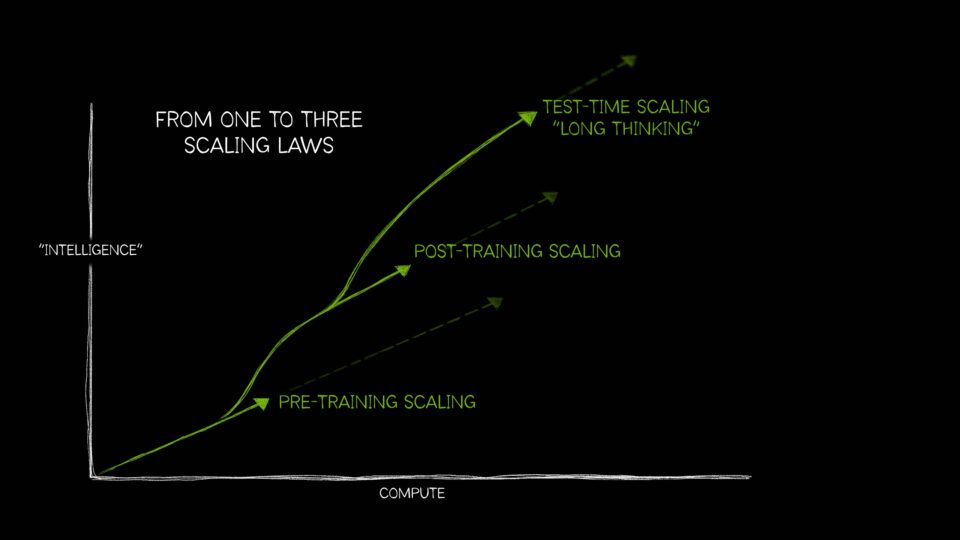
1. 사전 훈련 스케일링(Pretraining Scaling)
- AI 개발의 최초 법칙으로 훈련 데이터셋 크기, 모델 파라미터 수, 사용된 연산 자원 등 증가시키면, 모델의 지능과 정확도가 예측 가능하게 향상된다.
- 더 큰 모델에 더 많은 데이터를 제공하면 전반적인 성능이 향상
- 이를 실현하기 위해서는 연산 자원을 함께 확장해야 하며, 이는 대규모 훈련 워크로드를 처리할 수 있는 강력한 가속 컴퓨팅 자원의 필요
- 수십억~수조 개의 파라미터를 가진 트랜스포머(Transformer) 모델, 전문가 혼합 모델(Mixture of Experts), 분산 학습 기법 등 획기적인 모델 아키텍처 혁신을 이끌었으며, 모두 고성능 컴퓨팅 자원을 필요로 했음
- 전문가 혼합 모델(Mixture of Experts): 한 개의 프롬프트가 다양한 AI 모델 중에서 최적의 모델을 선택하는 전문가 혼합(MoE) 구조는 질문에 대한 응답 시 연산량을 줄여줌
- 인간은 계속해서 텍스트, 이미지, 오디오, 비디오, 센서 데이터 등 다양한 멀티모달 데이터를 생산하고 있으며, 이 데이터들은 더 강력한 차세대 AI 모델의 훈련에 활용될 것
- 사전 훈련 스케일링은 모델 크기, 데이터 크기, 연산 자원 크기 사이의 연관성을 기반으로 AI 성능을 향상시키는 핵심 원칙
2. 사후 훈련 스케일링(Post-training Scaling)
- 배경
- 사전 훈련된 초거대 언어 모델은 거액의 투자, 숙련된 전문가, 및 방대한 데이터셋이 필요함
- 일단 어떤 조직이 사전 훈련을 완료하고 모델을 공개하면, 다른 조직이나 개발자들이 이를 기반으로 후속 모델을 쉽게 개발할 수 있는 기반이 마련됨
- 사후 훈련 과정(Post-Training)은 기업과 개발자 커뮤니티 전반에서 추가적인 가속 컴퓨팅 수요를 창출
- 인기 있는 오픈소스 모델 하나가 수백 개, 심지어 수천 개의 파생 모델. ex) 라마, 미스트랄
- 다양한 목적에 맞춘 파생 모델 생태계를 개발하는 데는, 원래의 사전 훈련보다 최대 30배 더 많은 연산 자원이 필요
- 정의
- 특정 조직의 목적에 맞춰 모델의 특화된 성능을 향상시킴
- 사전 훈련이 AI 모델에게 기초적인 학습을 시키는 학교 교육이라면, 사후 훈련은 해당 직무에 맞는 실무 교육임
- LLM은 사후 훈련을 통해 감정 분석, 번역, 혹은 의료·법률 분야의 전문 용어를 이해할 수 있게 훈련됨
- 사후 훈련 기법 - 정확도, 효율성, 도메인 특화 성능을 추가로 개선
- 파인튜닝(Fine-Tuning): 추가적인 데이터로 모델을 특정 도메인이나 업무에 맞게 조정함. 내부 데이터를 활용하거나, 입력-출력 쌍을 이용한 방식으로 수행됨.
- 지식 증류(Distillation): 복잡한 대형 모델(teacher)의 출력을 단순한 경량 모델(student)에게 학습시키는 방식. 일반적으로 오프라인 증류 방식이 가장 많이 사용
- 강화 학습(Reinforcement Learning):
- 보상 모델을 통해 AI가 특정 목적에 맞는 결정을 내리도록 학습시킴.
- 예): 챗봇이 사용자로부터 ‘좋아요(👍)’ 반응을 보상으로 받아 개선되는 방식 (RLHF). 최근에는 AI 피드백 기반 강화 학습(RLAIF)도 등장했음
- Best-of-n 샘플링: 언어 모델이 여러 개의 응답을 생성하고, 그 중 보상 점수가 가장 높은 출력을 선택하는 방식. 모델 파라미터를 수정하지 않고 성능을 개선할 수 있음.
- 탐색 기반 기법(Search Methods): 다양한 결정 경로를 탐색한 후 최적의 응답을 선택하는 방식으로, 모델의 응답을 반복적으로 개선함.
- 합성 데이터(Synthetic Data): 실제 데이터에 AI가 생성한 데이터를 추가하여, 기존 훈련 데이터에 부족했던 드문 케이스(edge case)를 보완할 수 있음.
- 사후 훈련 스케일링 기법은 기존의 대형 모델을 다양하고 전문적인 목적에 맞게 활용할 수 있도록 진화시키며, AI 기술의 실질적 채택과 확산에 핵심적인 역할
3. 테스트 타임 스케일(Test-Time Scaling)
-
테스트 타임 스케일링은 추론 시점(inference time)에 더 많은 연산 자원을 사용해 정확도를 높이는 방식
-
AI 추론 모델(AI Reasoning Models)**이라는 새로운 범주의 **대형 언어 모델(LLM)을 가능하게 했음
- 새로운 AI 추론인 Reasoning AI 추론에 대해서는 여기를 참조하라!
- 복잡한 문제를 해결하기 위해 여러 번 추론을 수행하며, 과정을 단계적으로 설명함
-
AI의 사고력을 강화하기 위해 대규모 연산 자원을 필요로 하며, 이는 향후 고속 연산 컴퓨팅(Accelerated Computing)에 대한 수요를 더욱 가속화시킬 것임.
4. 참고
- NVIDIA 블로그: https://blogs.nvidia.com/blog/ai-scaling-laws/
- 미디엄 블로그: https://medium.com/@rendysatriadalimunthe/understanding-test-time-compute-a-new-mechanism-allowing-ai-to-think-harder-19e017abc540
- 허깅페이스 블로그: https://huggingface.co/blog/Kseniase/testtimecompute
- 튜닝 포스트: https://turingpost.co.kr/p/topic-26-test-time-compute
댓글남기기