DeepSpeed
DeepSpeed는 Microsoft에서 개발한 딥러닝 최적화 라이브러리로, 특히 대규모 모델 훈련을 효율적이고 확장성 있게 수행할 수 있도록 설계된 도구이다. DeepSpeed 에 대해 알아보고, 테스트한 코드를 정리해 보도록 하겠다.
1. DeepSpeed 개요
| 항목 | 설명 |
|---|---|
| 개발사 | Microsoft |
| 기반 | PyTorch |
| 목적 | 대규모 모델 학습 최적화 및 분산 학습 지원 |
| 대표 기능 | ZeRO optimizer, Mixed Precision, Model Parallelism, Pipeline Parallelism, DeepSpeed-Inference 등 |
2. DeepSpeed 핵심 아키텍처
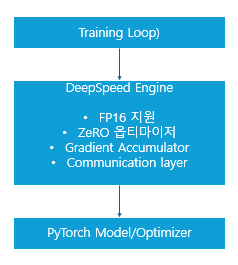
- DeepSpeed Engine: 모델, 옵티마이저, 스케줄러를 관리하며, 모든 학습 루프에 대한 효율적인 추상화 제공
- ZeRO Optimizer: GPU 메모리를 모델 상태, 그라디언트, 옵티마이저 상태로 나눠 분산 저장
- FP16 / Mixed Precision: 성능을 높이고 메모리 사용량을 줄임
- Communication Layer: NCCL 기반으로 분산 학습 수행
3. DeepSpeed 예제 (train.py)
import torch
import torch.nn as nn
import torch.nn.functional as F
import deepspeed
class SimpleModel(nn.Module):
def __init__(self, hidden_dim=128):
super().__init__()
self.fc1 = nn.Linear(784, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
def get_data():
# Dummy data (batch_size=32, input_dim=784)
x = torch.randn(32, 784)
y = torch.randint(0, 10, (32,))
return x, y
def main():
model = SimpleModel()
parameters = filter(lambda p: p.requires_grad, model.parameters())
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=parameters,
config="ds_config.json"
)
for step in range(100):
x, y = get_data()
x = x.to(model_engine.device)
y = y.to(model_engine.device)
outputs = model_engine(x)
loss = F.cross_entropy(outputs, y)
model_engine.backward(loss)
model_engine.step()
if __name__ == "__main__":
main()
4. DeepSpeed 설정 파일 (ds_config.json)
{
"train_batch_size": 32,
"gradient_accumulation_steps": 1,
"fp16": {
"enabled": true
},
"zero_optimization": {
"stage": 1
}
}
fp16.enabled: 자동 mixed precisionzero_optimization.stage: ZeRO 최적화 단계 (0~3)
5. 실행 방법
deepspeed train.py
또는 다중 GPU에서는 다음과 같이 실행함
deepspeed --num_gpus=4 train.py
댓글남기기