[실습] PDF 문서 기반 챗봇
이번 실습은 사용자가 문서를 업로드하면 문서 내용을 임베딩하고, 그 내용을 바탕으로 질문에 응답하는 간단한 PDF 문서 기반 챗봇 시스템을 만들어 본 것을 Python 소스 코드와 함께 내용을 정리해보겠다.
1. 현재 환경에 필수 컴포넌트 설치
pip install streamlit dotenv langchain langchain_community pdfminer.six
- streamlit 컴포넌트: 대화형 대시보드나 LLM 챗봇 UI를 빠르게 만들 수 있는 Python 스크립트를 웹 앱처럼 실행할 수 있게 해주는 프레임워크
- dotnev 컴포넌트:
.env파일에 저장된 환경변수를 Python 코드에서 불러오기 위한 패키지 - langchain 컴포넌트: 문서 QA, 에이전트, 체인 구성, Tool 사용, 메모리 관리 등 LLM 기반 애플리케이션 구축을 위한 프레임워크
- langchain_community 컴포넌트: FAISS, Chroma, HuggingFace, OpenAI 등의 커넥터 및 벡터 DB 연동 등 LangChain 커뮤니티에서 관리하는 플러그인, 도구, 래퍼들을 포함한 확장 패키지.
- pdfminer.six 컴포넌트: PDF 문서에서 텍스트를 추출하는 데 사용한 패키지
2. 필수 라이브러리 import 추가
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_community.chat_models import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import ChatMessage, HumanMessage, SystemMessage
from langchain.callbacks.base import BaseCallbackHandler
from pdfminer.high_level import extract_text
3. 환경 설정 및 임베딩 초기화
# 환경 변수 설정
load_dotenv()
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_KEY>"
# 임베딩 초기화 - 환경 변수 OPENAI_API_KEY를 자동으로 인식하여 OpenAI API에 접근함
embedding_model = OpenAIEmbeddings()
- load_dotenv():
.env파일에OPENAI_API_KEY=sk-xxxx가 있으면, 이 키가 시스템 환경 변수로 등록함 - embedding_model = OpenAIEmbeddings()
- 기능: OpenAI의 텍스트 임베딩 모델(기본적으로
text-embedding-ada-002)을 초기화함 - 사용 목적: 문장을 벡터(숫자 배열)로 변환해 유사도 검색, 벡터 DB 저장, 검색 기반 생성(RAG) 등에 사용됨
- 기능: OpenAI의 텍스트 임베딩 모델(기본적으로
4. MarkdownStreamHandler 클래스 정의
class MarkdownStreamHandler(BaseCallbackHandler):
"""
Streamlit 마크다운 컨테이너에 생성된 토큰을 실시간으로 스트리밍하는 사용자 정의 핸들러.
"""
def __init__(self, output_container, initial_content=""):
self.output_container = output_container
self.generated_content = initial_content
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.generated_content += token
self.output_container.markdown(self.generated_content)
-
용도: LangChain과 Streamlit을 연동하여 LLM(Large Language Model)이 생성하는 텍스트를 마크다운 형태로 실시간 출력하기 위한 사용자 정의 콜백 핸들러 클래스
-
주요 기능: LangChain의
on_llm_new_token이벤트 처리 -
사용처: 실시간 챗봇 UI, LLM 인터페이스 구현
-
__init__생성자(constructor)output_container: Streamlit의 출력 영역 (st.empty()또는st.container())을 전달받아 저장함initial_content: 초기 텍스트 내용을 지정할 수 있는 선택적 인자.- 이 값은 LLM이 토큰을 출력하기 전의 상태
-
on_llm_new_token 메서드
- LLM이 새 토큰을 생성할 때마다 자동 호출되는 함수
token: 현재 생성된 단일 토큰 문자열- 동작
- 기존
generated_content문자열에 새로운 토큰을 붙임 - 그 컨텐츠를
markdown()으로 출력 컨테이너에 업데이트함 - 결과적으로 사용자는 Streamlit 앱에서 LLM이 생성하는 응답을 실시간으로 확인할 수 있게 됨
- 기존
-
전체 흐름
- 사용자 질문을 입력하면 LangChain LLM이 응답 생성을 시작함
- MarkdownStreamHandle 핸들러는 LangChain에
callbacks=[MarkdownStreamHandler(...)]식으로 전달됨 - LLM이 응답 텍스트를 한 토큰씩 생성하면서
on_llm_new_token()이 반복 호출됨 - 그때마다
output_container.markdown(...)으로 실시간 업데이트가 이루어짐
5. PDF 텍스트 추출 함수 추가
def extract_text_from_pdf(file):
"""pdfminer를 사용하여 PDF 파일에서 텍스트 추출."""
try:
return extract_text(file)
except Exception as error:
st.error(f"PDF에서 텍스트 추출 중 오류 발생: {error}")
return ""
- 함수 명: extract_text_from_pdf
- 인자:
file– PDF 파일 객체 또는 경로 - 역할: 입력된 PDF 파일로부터 텍스트를 추출
- docstring: 함수 설명 (한글로 작성됨)
extract_text는pdfminer.high_level.extract_text함수로, PDF에서 텍스트를 추출함- PDF 내 페이지들을 파싱해 텍스트만 반환하고, 성공 시 바로 추출된 텍스트를 return 함
6. PDF 문서 업로드 함수 추가
def handle_uploaded_file(file):
"""업로드된 PDF 파일을 처리하고 벡터 스토어 준비."""
if not file: # 업로드 여부 확인
return None, None
# 파일 유형에 따라 텍스트 추출
document_text = extract_text_from_pdf(file) if file.type == 'application/pdf' else ""
if not document_text:
st.error("업로드된 PDF 파일에서 텍스트를 추출할 수 없습니다.")
return None, None
# 문서를 문서 단락(작은 청크)로 나누어 벡터화 준비
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200
)
document_chunks = text_splitter.create_documents([document_text])
st.info(f"{len(document_chunks)}개의 문서 단락이 생성되었습니다.")
# 유사성 검색을 위한 벡터 스토어 생성
vectorstore = FAISS.from_documents(document_chunks, embedding_model)
return vectorstore, document_text
-
전체 과정
- 사용자가 업로드한 PDF 파일을 처리함
- 텍스트를 추출하고,
- 텍스트를 청크 단위로 나눈 뒤,
- 임베딩하여 FAISS 벡터 DB에 저장
- LangChain 기반 문서 임베딩 처리 함수
- 실시간 처리 결과는 Streamlit으로 사용자에게 피드백을 제공함
-
handle_uploaded_file 함수
- 목적: PDF 파일을 업로드하면 텍스트를 뽑고 청크로 나눈 뒤 FAISS 벡터 스토어를 만들어 검색 준비를 완료함
- 반환값:
(vectorstore, document_text) vectorstore: FAISS 기반 벡터 DBdocument_text: 전체 추출된 텍스트
- 반환값:
- 목적: PDF 파일을 업로드하면 텍스트를 뽑고 청크로 나눈 뒤 FAISS 벡터 스토어를 만들어 검색 준비를 완료함
-
업로드 여부 확인: 파일이 업로드되지 않은 경우 → 처리를 중단하고
None반환. -
텍스트 추출:
- PDF인 경우에만
extract_text_from_pdf()함수를 통해 텍스트 추출. - 그 외 파일 형식은 현재 지원하지 않음 (추후 DOCX 등 확장 가능).
- 추출 실패 시 다음과 같이 에러 표시
- PDF인 경우에만
-
텍스트를 문서 단락으로 분할
- LangChain의
CharacterTextSplitter를 사용해 긴 텍스트를 나눔 - 파라미터:
chunk_size=1000: 최대 1,000자씩 나눔chunk_overlap=200: 단락 간 중복 200자 포함 (문맥 유지용)
- LangChain의
-
벡터 스토어(Faiss) 생성
- 생성된 텍스트 단락들을
embedding_model로 임베딩하고, FAISS 벡터 스토어에 저장함 - 이 객체는 추후 유사도 기반 검색에 사용됩니다 (예: RAG 챗봇).
- 생성된 텍스트 단락들을
-
return
vectorstore: 질의-응답, 검색 등에 활용document_text: 원문 전체, 로그나 요약 등에 활용 가능
7. RAG를 사용한 응답 생성 함수 추가
def get_rag_response(user_query, vectorstore, callback_handler):
"""검색된 문서를 기반으로 사용자 질문에 대한 응답 생성."""
if not vectorstore:
st.error("벡터 스토어가 없습니다. 문서를 먼저 업로드하세요.")
return ""
# 가장 유사한 문서 3개 검색
retrieved_docs = vectorstore.similarity_search(user_query, k=3)
retrieved_text = "\n".join(f"문서 {i+1}: {doc.page_content}" for i, doc in enumerate(retrieved_docs))
print(retrieved_text)
# LLM 설정
chat_model = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True, callbacks=[callback_handler])
# RAG 프롬프트 생성
rag_prompt = [
SystemMessage(content="제공된 문서를 기반으로 사용자의 질문에 답변하세요. 정보가 없으면 '모르겠습니다'라고 답변하세요."),
HumanMessage(content=f"질문: {user_query}\n\n{retrieved_text}")
]
try:
response = chat_model(rag_prompt)
return response.content
except Exception as error:
st.error(f"응답 생성 중 오류 발생: {error}")
return ""
- get_rag_response()
- RAG (Retrieval-Augmented Generation) 방식으로 동작하는 LangChain 기반 Q&A 시스템의 핵심 로직
- 사용자가 입력한 질문에 대해, 벡터 스토어에서 관련 문서를 검색하고, 해당 문서 내용을 바탕으로 GPT 모델이 답변을 생성함
- 목적: 사용자 질문(
user_query)을 입력 받아, 벡터 스토어(vectorstore)에서 관련 문서를 검색한 후, LLM에게 해당 문서와 함께 질문을 전달해 정확하고 근거 있는 답변을 생성함
- 벡터 스토어 체크
- 문서가 업로드되지 않아
vectorstore가 없는 경우 에러 메시지를 출력하고 함수 종료.
- 문서가 업로드되지 않아
- 문서 검색
vectorstore에서 질문과 가장 유사한 3개의 문서를 검색함similarity_search()는 내장된 문장 임베딩을 기반으로 벡터 유사도 계산을 수행함- 검색된 문서 내용을 문자열로 병합하여 출력 형식으로 저장함
- Streamlit에는 출력되지 않고 콘솔에만 출력됨 (
print()).
- gpt-4o-mini LLM 설정
- LangChain의
ChatOpenAI클래스를 사용해 GPT-4o-mini 모델 인스턴스를 초기화함 - 옵션
temperature=0: 가장 확정적인(정확도 높은) 응답을 생성streaming=True: 실시간 토큰 스트리밍 가능 (UI에 점진적 출력)callbacks=[callback_handler]:MarkdownStreamHandler등 스트리밍 핸들러 전달
- LangChain의
- 프롬프트 구성 (RAG 방식)
SystemMessage: LLM에게 역할을 지정함 (“문서를 기반으로만 답하라”, “모르면 모른다고 말하라”)HumanMessage: 실제 사용자 질문 + 검색된 문서 내용
- 응답 생성
chat_model()에 프롬프트를 전달하여 응답을 생성하고, 응답 내용을 리턴함
| 항목 | 설명 |
|---|---|
| 입력값 | user_query (질문), vectorstore (문서 벡터 DB), callback_handler (토큰 스트리밍 핸들러) |
| 핵심 기능 | 관련 문서 검색 → 프롬프트 구성 → LLM 호출 → 응답 생성 |
| 반환값 | LLM이 생성한 최종 응답 문자열 |
| 사용 기술 | LangChain, OpenAI GPT, FAISS 벡터 검색, Streamlit 오류 출력 |
| 목적 | RAG 방식 Q&A 챗봇에서 사용자 질문에 대해 문서를 기반으로 신뢰성 있는 응답 제공 |
8. Streamlit UI 설정
st.set_page_config(page_title="PDF 문서 기반 챗봇")
st.title("📄 PDF 문서 기반 챗봇")
- 용도
- Streamlit 앱의 초기 페이지 설정과 타이틀 구성을 담당함
- 주로 웹 페이지를 사용자 친화적으로 보이게 하고, 주제를 명확히 전달하기 위해 사용함
- st.set_page_config(…)
- Streamlit 앱의 메타데이터(페이지 설정)를 지정함
- 주요 파라미터:
- page_title: 브라우저 탭에 표시될 제목 → 예: 📄 PDF 문서 기반 챗봇
- 이 외에도
page_icon,layout,initial_sidebar_state등을 설정할 수 있음.
- st.title(…)
- Streamlit 앱 상단에 크게 타이틀을 표시함
9. 세션 상태의 변수 초기화
# vectorstore 상태 변수 초기화
if "vectorstore" not in st.session_state:
st.session_state["vectorstore"] = None
# 사용자의 대화 내역(chat_history)을 저장함
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = [
ChatMessage(role="assistant", content="안녕하세요? 업로드된 문서 내용의 범위에서만 질문해 주세요.")
]
- 전체 흐름
- 사용자가 문서를 업로드 → 문서 내용을 벡터화하여
vectorstore에 저장 - 사용자 질문 입력 →
chat_history에 질의-응답을 순차 저장 streamlit_chat등 UI 구성 요소에서 이 상태를 기반으로 메시지를 렌더링
- 사용자가 문서를 업로드 → 문서 내용을 벡터화하여
- st.session_state
- Streamlit 앱은 리랜더링(재실행) 될 때마다 변수 상태가 초기화될 수 있음
- 이를 방지하기 위해 Streamlit은
st.session_state라는 세션별 상태 저장소를 제공 - 이 구조를 통해 유저 인터랙션 중에도 상태(값)를 기억할 수 있음
vectorstore상태 변수 초기화vectorstore는 FAISS나 Chroma 같은 벡터 검색 데이터베이스 객체를 저장하기 위해 사용- 처음 실행 시, 존재하지 않는 경우
None으로 초기화하여 이후 코드에서 오류를 방지
chat_history상태 변수 초기화chat_history는 사용자의 대화 내역(채팅 로그) 를 저장함- 존재하지 않으면 초기값으로 “assistant” 역할의 환영 메시지를 하나 등록함
ChatMessage는 일반적으로langchain이나 Streamlit Chat Components에서 사용하는 데이터 구조
10. PDF 파일 업로드 처리
# 1. 파일 업로드 위젯 생성
uploaded_file = st.file_uploader("PDF 문서만 업로드해 주세요!:", type=["pdf"])
# 2. 업로드된 파일이 이전과 다르면 처리
if uploaded_file and uploaded_file != st.session_state.get("uploaded_file"):
# 3. 파일 처리 함수 호출
vectorstore, document_text = handle_uploaded_file(uploaded_file)
# 4. 처리된 결과를 세션 상태에 저장
if vectorstore:
st.session_state["vectorstore"] = vectorstore
st.session_state["uploaded_file"] = uploaded_file
- 전체 흐름
| 요소 | 설명 |
|---|---|
st.file_uploader |
PDF 업로드 UI 구성 |
handle_uploaded_file() |
PDF → 텍스트 추출 → 벡터 임베딩 → vectorstore 생성 |
st.session_state |
벡터스토어와 업로드 파일 상태 유지 |
| 목적 | 사용자 질문을 문서 기반으로 응답하기 위한 RAG 챗봇용 준비 코드 |
-
파일 업로드 위젯 생성
- Streamlit에서 파일 업로드 위젯을 생성.
- 사용자는 PDF 문서만 업로드할 수 있음 (
type=["pdf"]) - 업로드된 파일은
uploaded_file변수에 저장됨 (파일 객체 형태)
-
업로드된 파일이 이전과 다르면 처리
- 사용자가 새로 파일을 업로드했는지 확인 -> 동일한 파일을 다시 처리하지 않도록 방지하는 체크
st.session_state.get("uploaded_file")을 통해 이전에 업로드된 파일과 비교
-
파일 처리 함수 호출
handle_uploaded_file()함수는 PDF 파일을 받아서, 1) 텍스트 추출: PDF → 텍스트, 2) 벡터화 및 저장: 텍스트를 분할하고 임베딩하여 FAISS, Chroma 등 벡터스토어에 저장- Return value
vectorstore: 임베딩이 저장된 검색 가능한 벡터 데이터베이스document_text: 전체 문서의 원문 텍스트 (옵션)
-
처리된 결과를 세션 상태에 저장
- 유효한 벡터스토어가 생성된 경우에만:
vectorstore를st.session_state에 저장하여, 이후 챗봇 질문 등에 활용할 수 있도록 함uploaded_file도 저장하여 동일 파일 중복 업로드 방지 또는 상태 유지용으로 사용
- 유효한 벡터스토어가 생성된 경우에만:
11. 채팅 기록 표시
chat_container = st.container()
with chat_container:
for message in st.session_state.chat_history:
st.chat_message(message.role).write(message.content)
- 전체 흐름: Streamlit의
st.chat_message()기능을 사용하여, 저장된 채팅 기록(chat_history)을 화면에 출력하는 부분 - chat_container = st.container()
st.container()는 Streamlit 내에서 UI 영역을 하나 생성하는 명령- 이
chat_container안에서 다양한 요소를 묶어채팅 메시지를 렌더링할 수 있음 - 나중에 이 컨테이너에만 내용을 갱신하거나 새로 렌더링할 수도 있음
- with chat_container:
chat_container블록 내부에서 UI 요소를 렌더링하겠다는 의미- 아래에 나오는
st.chat_message(...)들이 이 컨테이너 안에 출력됨
- for message in st.session_state.chat_history:
- Streamlit의
session_state안에 저장된chat_history리스트를 순회함 - 이 리스트에는
ChatMessage객체들이 들어 있음. 예:ChatMessage(role="user", content="안녕!")
- Streamlit의
- st.chat_message(message.role).write(message.content)
st.chat_message(...)는 Streamlit의 채팅용 UI 구성 요소message.role에는"user"또는"assistant"등이 들어가며, 채팅 말풍선의 스타일이 다르게 출력함.write(message.content)를 통해 해당 말풍선에 실제 텍스트(내용)를 출력함
12. 사용자 질문 입력
if user_query := st.chat_input("업로드된 문서를 기반으로 질문해 주세요:"):
st.session_state.chat_history.append(ChatMessage(role = "user", content = user_query))
with chat_container:
st.chat_message("user").write(user_query)
- 전체 요약
| 구성 요소 | 설명 |
|---|---|
st.chat_input() |
채팅용 텍스트 입력창 생성 |
:= (walrus operator) |
입력값이 있을 때만 조건 실행 |
st.session_state.chat_history.append() |
질문을 대화 기록에 저장 |
st.chat_message("user").write(...) |
화면에 사용자 질문 출력 |
chat_container |
채팅 메시지들을 묶어 출력하는 공간 |
- if user_query := st.chat_input(…):
st.chat_input("...")는 채팅 인터페이스 하단에 입력창을 생성함- 사용자가 질문을 입력하고 Enter를 누르면 그 내용이
user_query에 저장됨 :=는 파이썬의 walrus operator로, 값 할당과 조건문을 동시에 처리함
- st.session_state.chat_history.append(…)
- 사용자의 질문을
ChatMessage객체로 생성하여chat_history에 추가함 - 이렇게 하면 Streamlit 앱이 다시 실행되더라도 이 대화가 유지됨
- 사용자의 질문을
- with chat_container:
- 이전에 정의한
chat_container안에 출력하겠다는 의미
- 이전에 정의한
- st.chat_message(“user”).write(user_query)
- 사용자 역할(
"user")로 채팅 말풍선을 만들어 입력한 질문을 바로 출력함 - 즉, 사용자가 질문을 제출하자마자 화면에 실시간으로 표시됨
- 사용자 역할(
13. 응답 생성
with st.chat_message("assistant"):
stream_output = MarkdownStreamHandler(st.empty())
assistant_response = get_rag_response(user_query, st.session_state.get("vectorstore"), stream_output)
if assistant_response:
st.session_state.chat_history.append(ChatMessage(role="assistant", content = assistant_response))
- 전체 흐름
- Streamlit 기반 문서 챗봇에서 사용자의 질문에 대해 AI 응답을 생성
- 해당 응답을 화면에 출력하며, 대화 기록(chat history)에 저장하는 부분
- RAG (Retrieval-Augmented Generation) 방식과 스트리밍 출력을 함께 사용
| 단계 | 설명 |
|---|---|
| 1 | st.chat_message("assistant")로 AI 말풍선 공간 생성 |
| 2 | MarkdownStreamHandler로 실시간 스트리밍 출력 핸들러 생성 |
| 3 | get_rag_response()로 RAG 방식의 AI 답변 생성 |
| 4 | 응답이 있으면 chat_history에 추가하여 상태 유지 |
- with st.chat_message(“assistant”):
- Streamlit의 채팅 메시지 말풍선을 assistant 역할로 생성함
- 이 블록 내부에 있는 출력 내용은 모두 AI 응답 말풍선으로 표시됨
- stream_output = MarkdownStreamHandler(st.empty())
st.empty()는 Streamlit에 빈 자리 표시용 UI 공간을 만듭니다. (나중에 내용을 동적으로 채움)MarkdownStreamHandler는 LLM 응답을 한 줄씩 스트리밍 형식으로 보여주는 출력 핸들러- LLM 응답을 한 번에 출력하지 않고, 조금씩 점점 나타나는 효과를 주는 데 사용됨
- assistant_response = get_rag_response(…)
- 사용자 질문(
user_query)에 대해 답변을 생성하는 핵심 함수 - 내부적으로, 1)
vectorstore를 통해 문서 검색, 2) 검색된 문서와 함께 프롬프트 생성, 3) LLM을 호출하여 답변 생성, 4) 생성 중간 결과를stream_output을 통해 실시간 표시 - LangChain + OpenAI 또는 HuggingFace 모델을 사용하는 RAG 파이프라인 함수
- 사용자 질문(
- if assistant_response:
- LLM이 유효한 응답을 반환했다면: 1) 해당 내용을
chat_history에 추가하여, 2) Streamlit 앱이 다시 실행될 때도 이 응답이 유지되도록 함
- LLM이 유효한 응답을 반환했다면: 1) 해당 내용을
14. 실행 화면
-
먼저 컴파일 에러가 없는 지 아래와 같이 확인함
python faiss-rag-streamlit.py -
아래 화면 대로, 컴파일 에러가 발생하지 않았다면 streamlit run 을 통해 실행시킴.
streamlit run faiss-rag-streamlit.py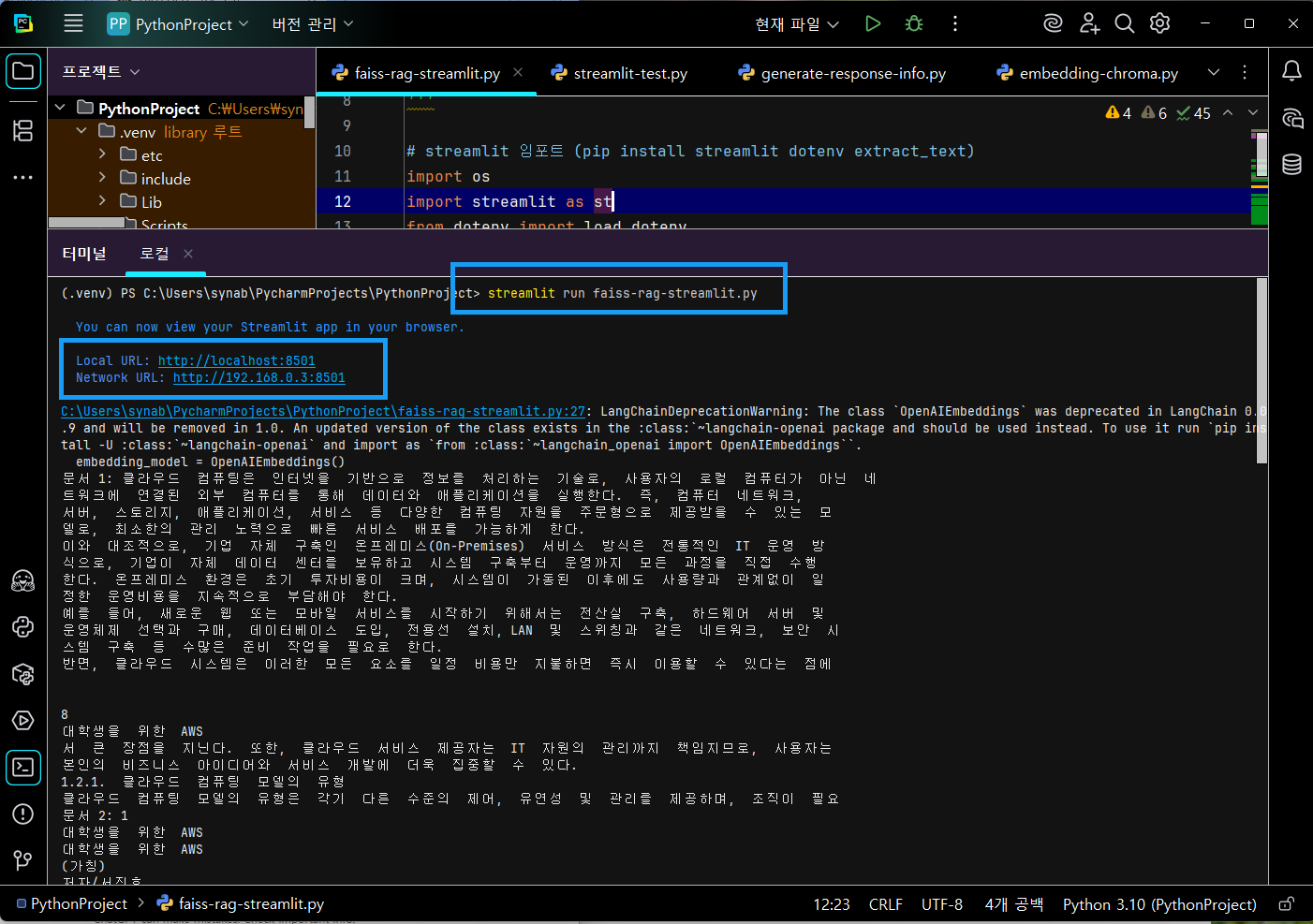
-
위의 화면에서 보듯이, 여러분의 웹 브라우저를 실행시켜 로컬 URL 주소나 네트워크 URL 둘 중 하나만 접속하면 아래와 같은 streamlit 웹 화면이 나타난다.
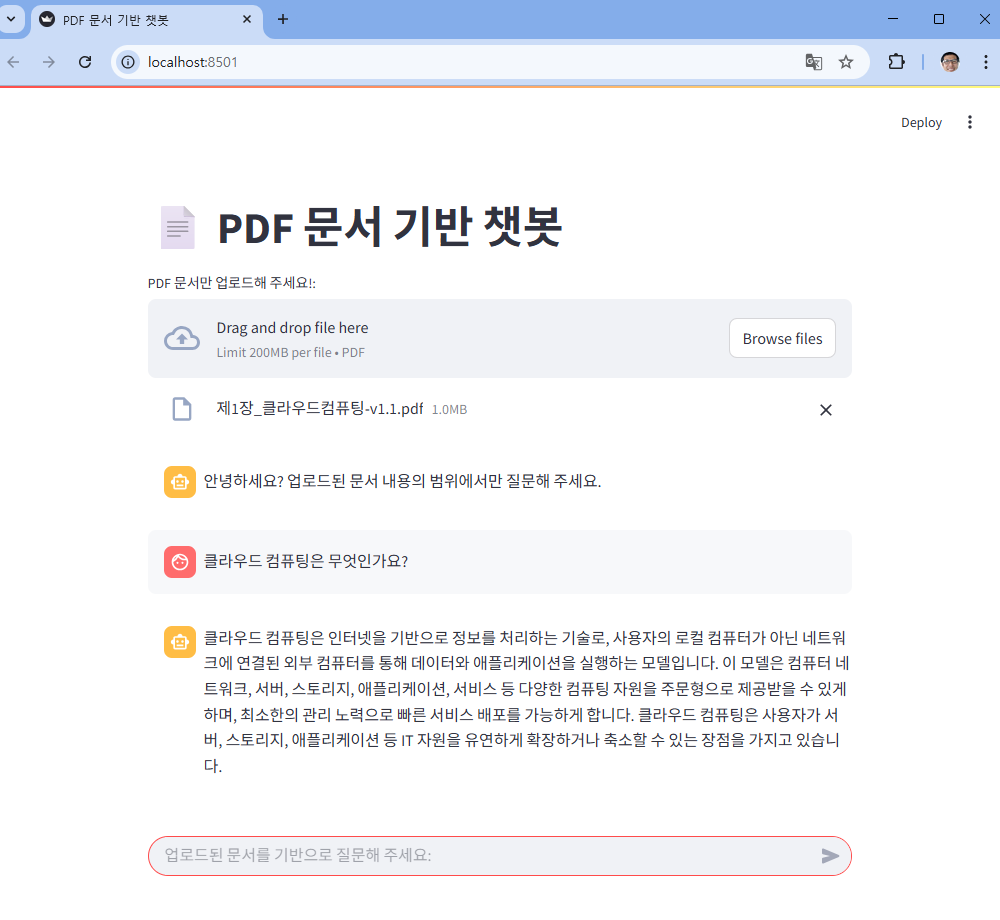
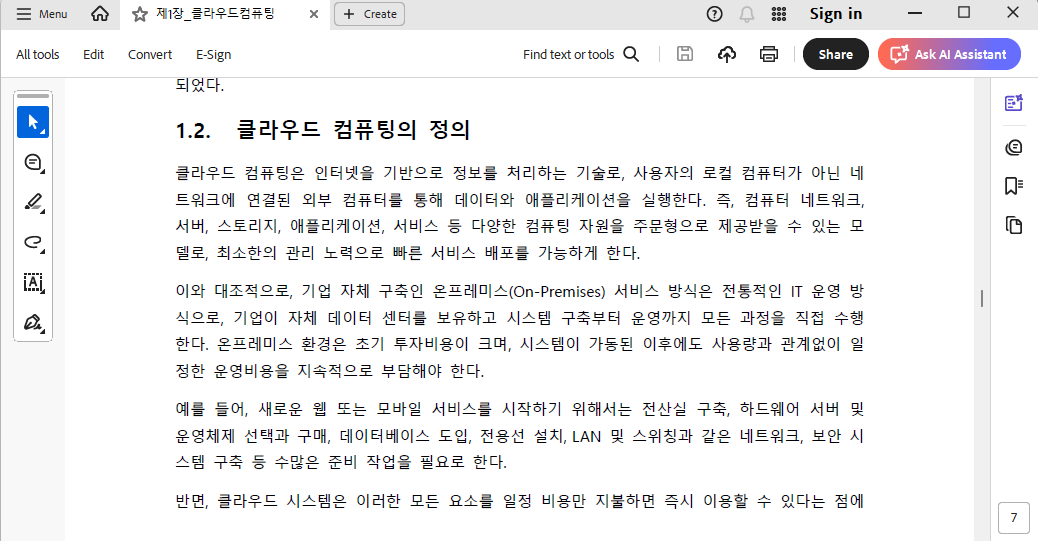
- 위의 화면에서 “클라우드 컴퓨팅은 무엇인가요?” 라는 질문을 챗봇에 질문했는데, 그것에 대한 답변이다. 이러한 답변이 환각이 아닌 올바르게 답변을 했는지 아래의 PDF 원본을 찾아 확인하면 된다.
댓글남기기