[실습] 부동산 데이터를 Chroma에 임베딩 저장하기
간단한 부동산 정보 데이터를 크로마(Chroma) 벡터 데이터베이스에 임베딩해서 저장하고 유사성을 검색하는 핸즈 온 실습을 한번 정리해 보자! 참고로 프로그램 기본 환경은 Python 3.10.10 버전과 크로마 벡터 데이터베이스 0.6.3 버전을 사용했으며, Embedding 데이터 저장 영역 중심으로 개발한 예제 소스 코드이다. 여러분은 아래와 같이 순서대로 따라해 보기 바란다.
1. chroma 벡터 데이터베이스와 sentence_transformers 설치
- 로컬 환경의 콘솔에서 아래의 명령어에서 “!” 를 삭제하고 실행한다. 그러나, 노트북이나 구글 코드랩에서 실행할 때에는 “!”를 앞 줄에 넣고 실행한다.
!pip install chromadb
!pip install sentence-transformers
2. 간단한 부동산 정보를 embedding 생성하기
sentences = [
'한강 상류 근처에 위치한 세련되고 전용 발코니가 있는 방 3개가 있는 타운 하우스',
'아늑한 벽난로가 있는 북한산 속의 평화로운 방 4개가 있는 목조 주택.',
'공용 피트니스가 있는 활기찬 강남에 있는 세련된 오피스텔.',
'아름다운 풍경이 펼쳐지는 전원에 위치한 매력적인 방 2개가 있는 전원 주택.',
'넓은 거실이 있는 대학 근처의 밝은 방 1개가 있는 오피스텔.',
'도심 한 가운데에 위치한 루프탑 테라스가 있는 모던한 방 1개와 침실 1가 있는 복층 원룸.'
]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
SentenceTransformer모델을 사용하여 한글 문장들을 문장 임베딩(sentence embedding)으로 변환하는 매우 실용적인 코드- setences 리스트는 부동산 매물 설명 같은 문장들로 구성되어 있으며, 임베딩할 문장 집합이다.
- 각 문장은 다양한 지역, 특징, 방 개수 등을 포함하고 있어 유사도 분석이나 검색 등에 유용한 특성을 담았다.
- from sentence_transformers import SentenceTransformer
sentence-transformers라이브러리는 문장을 고차원 벡터로 변환해주는 강력한 도구- 사전 학습(pretrained)된 다양한 Transformer 기반 모델을 제공하며,
BERT,RoBERTa,MiniLM등의 경량 모델도 사용 가능함
- model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
'all-MiniLM-L6-v2'는 HuggingFace와 SentenceTransformers에서 제공하는 빠르고 효율적인 문장 임베딩 모델- 이 모델은 영어에 최적화되어 있지만, 간단한 한글 문장에도 꽤 잘 작동함
MiniLM은 파라미터가 작아 빠르며, 다양한 NLP downstream task에서 성능 대비 속도 효율이 높음
- embeddings = model.encode(sentences)
- 임베딩 모델: 텍스트(혹은 이미지 등 다양한 데이터)를 수치화된 고정 크기의 벡터(vector)로 변환해주는 모델
- 문장 간 유사도 비교 (코사인 유사도)
- 벡터 기반 검색 (FAISS, ChromaDB 등과 연동)
- 클러스터링 또는 시각화 (t-SNE, UMAP)
- RAG 기반 질의응답 시스템에 활용
sentences리스트 안의 각 문장을 임베딩 벡터(예: 384차원)로 변환함- 결과는
embeddings라는 NumPy 배열로 반환되며, 각 문장은 고정된 차원의 벡터 표현을 갖게 됨
- 임베딩 모델: 텍스트(혹은 이미지 등 다양한 데이터)를 수치화된 고정 크기의 벡터(vector)로 변환해주는 모델
3. Chroma DB 클라이언트 초기화
client = chromadb.Client()
- Chroma 벡터 데이터베이스에 접속하기 위해 클라이언트 인스턴스를 생성하는 코드
- Chroma DB에 접근할 수 있는 클라이언트를 생성하여:
- 벡터 임베딩 데이터를 저장, 검색, 업데이트할 수 있도록
- Chroma의 다양한 API 기능(예:
add,get,query)을 사용할 수 있게 해줌
| 메서드 | 설명 |
|---|---|
chromadb.Client() |
메모리 기반(in-memory) 클라이언트. 프로그램 종료 시 데이터 사라짐. |
chromadb.PersistentClient(path="...") |
디스크에 영구 저장되는 버전. 서버나 장기 저장에 적합. |
4. 컬렉션 생성하면서 불러오기
collection_name = "Apt101"
collection = client.get_or_create_collection(collection_name)
| 항목 | 설명 |
|---|---|
collection_name = "Apt101" |
컬렉션 이름을 "Apt101"으로 설정함 |
client.get_or_create_collection(name) |
해당 이름의 컬렉션이 있으면 불러오고, 없으면 새로 생성 |
- 컬렉션(Collection)
- Chroma DB에서 데이터를 저장하는 논리적 공간 또는 벡터 그룹
- 각각의 collection은 id (unique key), document (문장 또는 텍스트), embedding (벡터), metadata (추가 필드: 예. 위치, 가격 등) 등을 포함
"Apt101"이라는 컬렉션을 사용하여 문장 임베딩 벡터와 관련 데이터를 저장 -> 이미 같은 이름의 컬렉션이 있다면 재사용, 없다면 자동 생성
| 메서드 | 설명 |
|---|---|
get_collection(name) |
해당 이름의 컬렉션이 존재하면 반환, 없으면 에러 발생 |
create_collection(name) |
항상 새로 생성. 동일한 이름이 있으면 에러 |
get_or_create_collection(name) |
가장 실용적. 자동 생성 또는 로딩 처리 |
5. 임베딩 및 메타 데이터 저장
collection.add(
ids=[str(i) for i in range(len(sentences))],
embeddings=embeddings.tolist(),
metadatas=[{"description": desc} for desc in sentences]
)
-
Chroma 벡터 데이터베이스의 컬렉션(
collection)에 여러 개의 벡터와 관련 메타데이터를 한 번에 추가(add)함. -
ids=[str(i) for i in range(len(sentences))]
- 각 문장에 대한 고유한 ID 리스트를 만듦
- 예: 문장이 6개라면
["0", "1", "2", "3", "4", "5"] - ⚠️
id는 Chroma에서 고유해야 하며, 나중에 삭제/업데이트 시에도 필요함
-
embeddings=embeddings.tolist()
- 문장 임베딩은 기본적으로 NumPy 배열이므로,
.tolist()로 리스트 형식으로 변환 - 각 벡터는 보통 384차원(
MiniLM-L6-v2) 또는 768차원이 있다.
- 문장 임베딩은 기본적으로 NumPy 배열이므로,
-
metadatas=[{“description”: desc} for desc in sentences]
-
각 문장에 대해 메타데이터 딕셔너리를 생성함
-
이
description필드는 나중에 metadata 기반 검색이나 RAG 응답에 문장을 포함할 때 유용함
-
6. 벡터 데이터베이스 검색을 위한 쿼리 생성
query = "강남 오피스텔"
query_embeddings = model.encode([query])
- 사용자가 검색하거나 질문한 텍스트 질의(Query) -> “강남에 있는 오피스텔” 관련된 문장
- query_embeddings = model.encode([query])
SentenceTransformer모델을 사용해 이 문장을 임베딩 벡터로 변환함- 반환 결과는 2차원 배열 (1, 384)로, 단일 문장이라도 리스트로 넣는 것이 중요
- Chroma DB의
collection.query()함수에서 다른 벡터들과 코사인 유사도를 계산할 수 있는 형태
7. Chroma DB 에서 유사도 검색
results = collection.query(
query_embeddings = query_embeddings.tolist(),
n_results = 1, # 질문과 답변의 유사도가 가장 높은 순으로 개수, 1은 1개만 출력.
include = ['metadatas', 'distances'] # 메타 데이터와 거리 값 포함
)
query_embeddings로부터 Chroma 컬렉션에서 가장 유사한 문장을 1개 검색하고, 그에 대한 메타데이터와 거리값(유사도)를 함께 반환- query_embeddings = query_embeddings.tolist()
SentenceTransformer가 생성한 임베딩은 NumPy 배열- Chroma는 Python 리스트 형식을 요구하므로
.tolist()로 변환
- n_results = 1
- 유사한 결과 중에서 가장 가까운 하나만 반환
- include = [‘metadatas’, ‘distances’]
| 항목 | 설명 |
|---|---|
'metadatas' |
각 결과에 저장된 메타데이터 반환 (ex. 원래 문장, 설명 등) |
'distances' |
쿼리 벡터와 저장된 벡터 간의 거리 값 (작을수록 유사함) |
- results: 유사한 문장 + 거리 + 메타데이터가 포함된 딕셔너리 결과
8. 결과 출력하기
for idx, (metadata, distance) in enumerate(zip(results['metadatas'][0], results['distances'][0])):
print(f"Result {idx+1}: {metadata['description']}(Distance: {distance})")
- 앞에서 얻은
results딕셔너리에서 검색 결과들을 순회하며, 각 결과의 설명(description)과 유사도 거리(distance)를 사람이 읽을 수 있게 출력 - zip(results[‘metadatas’][0], results[‘distances’][0])
results['metadatas']와results['distances']는 각각 2차원 리스트- 이유: 쿼리가 여러 개인 경우를 지원하기 때문
- 따라서
[0]으로 첫 번째 쿼리의 결과만 선택함 - zip()`을 사용해 각 결과의 메타데이터와 거리값을 쌍으로 묶음
- for idx, (metadata, distance) in enumerate(zip(…))
enumerate()는 인덱스 번호도 함께 제공함idx는 결과 번호 (0,1,2, …)metadata['description']는 문장 설명distance는 쿼리와의 거리 (작을수록 더 유사)
- print(f”Result {idx+1}: {metadata[‘description’]}(Distance: {distance})”)
- 결과 번호는
1부터 출력 (idx + 1) - 유사한 문장을 보여주고, 괄호 안에 거리값 표시
- 결과 번호는
9. 실행 결과
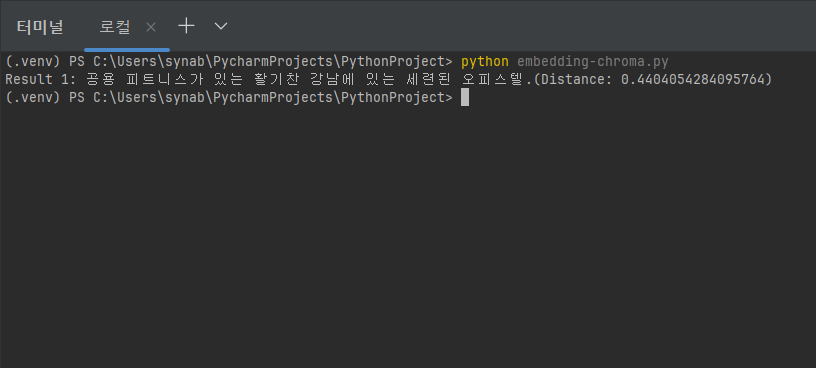
- python embedded-chroma.py 로 파이썬 앱을 실행하면, ‘강남 오피스텔’ 질문에 대해 첫번째 결과가 위의 화면에 보여준다.
댓글남기기