[실습] AI Toolkit for Visual Studio Code 사용하기
이번 마이크로소프트 빌드 2025 행사는 AI 개발자들에게 좀 더 모델과 에이전트, 앱 개발을 사용하기 쉽게 하기 위해 촛점을 맞추었다. VS Code 내에서 생성형 AI 앱 개발을 전방위 지원하기 위해 AI Toolkit for Visual Studio Code를 출시했다.
그렇다면, AI Toolkit (이하, AI Toolkit for Visual Studio Code 줄임말)이 무엇이고, 어떠한 주요 특징이 있는지 정리해 보겠다. 또한, AI Toolkit 설치 방법과 모델 카탈로그와 카드, 그리고 플레이그라운드에서 모델 파라미터를 조정하고 작성한 파이썬 코드로 실행한 방법도 포함한다.
1. AI Toolkit이란 무엇인가?
- Visual Studio Code용 강력한 확장 기능으로, 에이전트 개발을 간소화해 줌
- Anthropic, OpenAI, GitHub 등 다양한 제공업체의 모델을 탐색하고 평가하거나, ONNX 및 Ollama를 사용해 로컬에서 모델을 실행할 수 있음
- 프롬프트 생성, 빠른 시작 도구, MCP 툴과의 통합을 통해 몇 분 만에 에이전트를 구축하고 테스트할 수 있음
-
주요 특징
특징 설명 스크린샷 Model Catalog 다양한 소스에서 AI 모델을 탐색하고 접근할 수 있음. GitHub, ONNX, Ollama, OpenAI, Anthropic, Google 모델을 간편하게 검색하고 활용할 수 있음 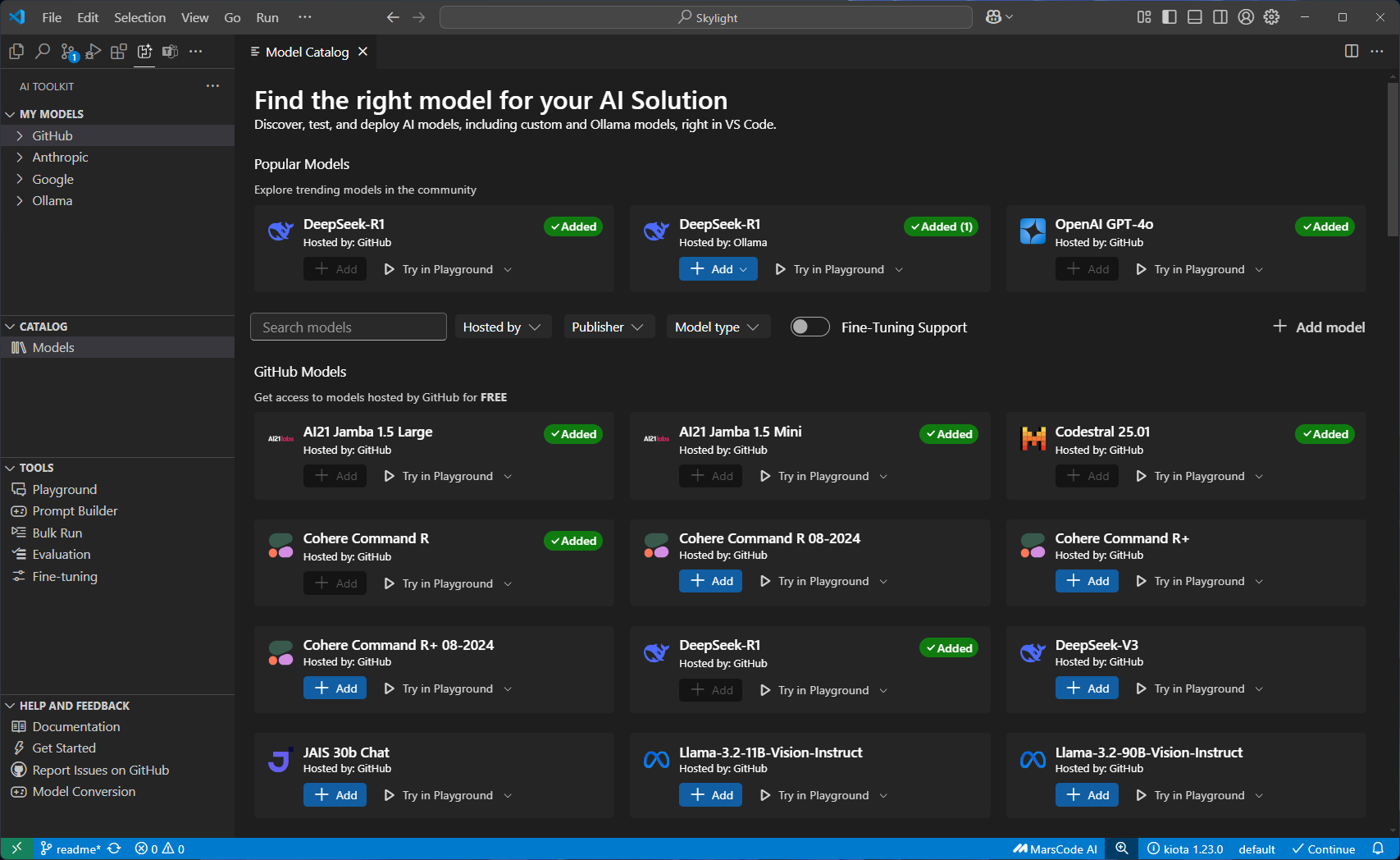
Playground 실시간 모델 테스트를 위한 인터랙티브 채팅 환경. 다양한 프롬프트, 파라미터, 이미지 및 첨부파일과 같은 멀티모달 입력을 활용하여 실험할 수 있음. 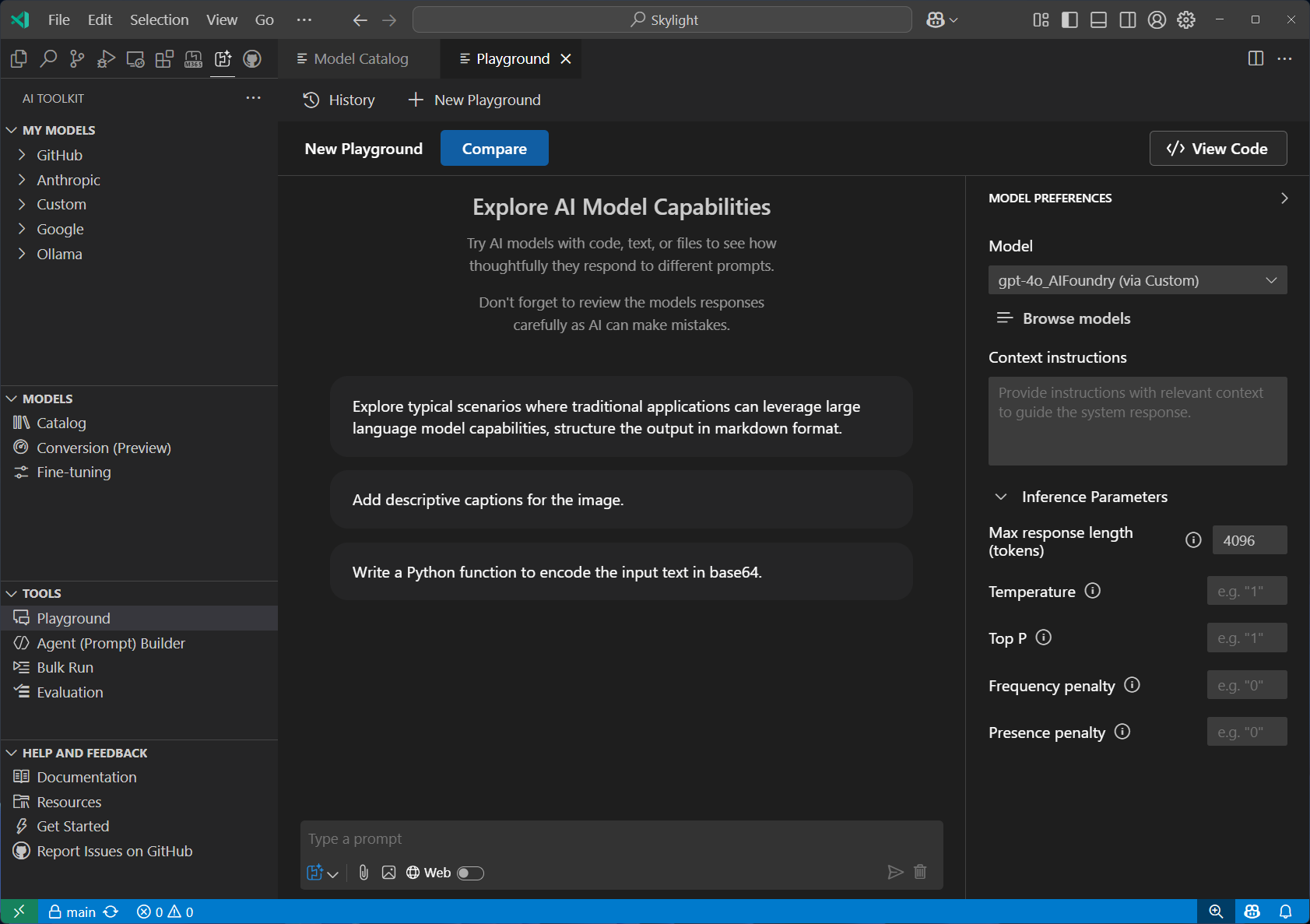
Prompt(Agent) Builder 간소화된 프롬프트 엔지니어링 및 에이전트 개발 워크플로우. 정교한 프롬프트를 생성하고 MCP 도구를 통합하며, 구조화된 출력으로 프로덕션 수준의 코드를 생성할 수 있음. 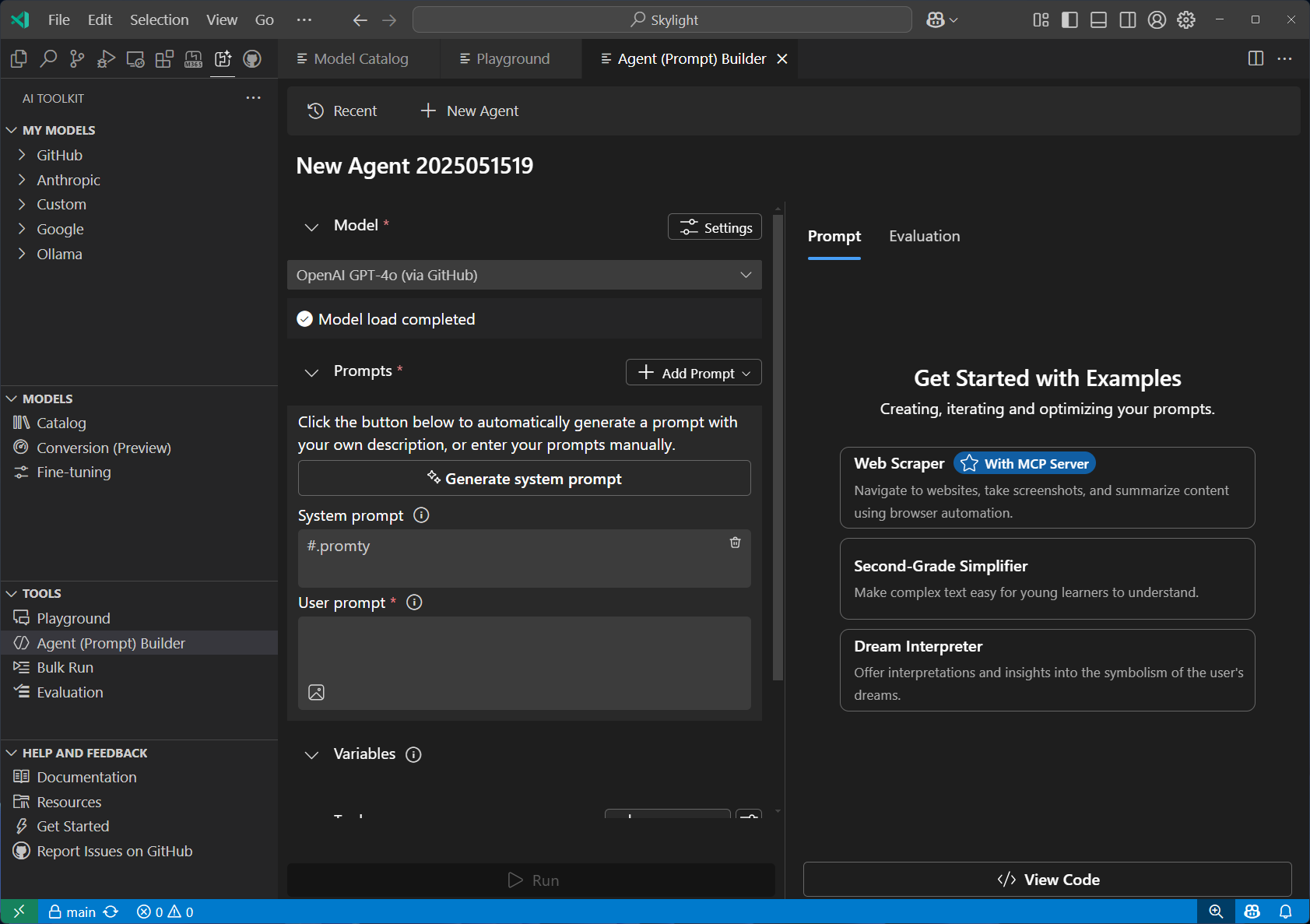
Bulk Run 여러 모델을 대상으로 동시에 배치 프롬프트 테스트를 실행함. 다양한 입력 시나리오에서 모델 성능을 비교하고 대규모 테스트를 수행하는 데 이상적임. 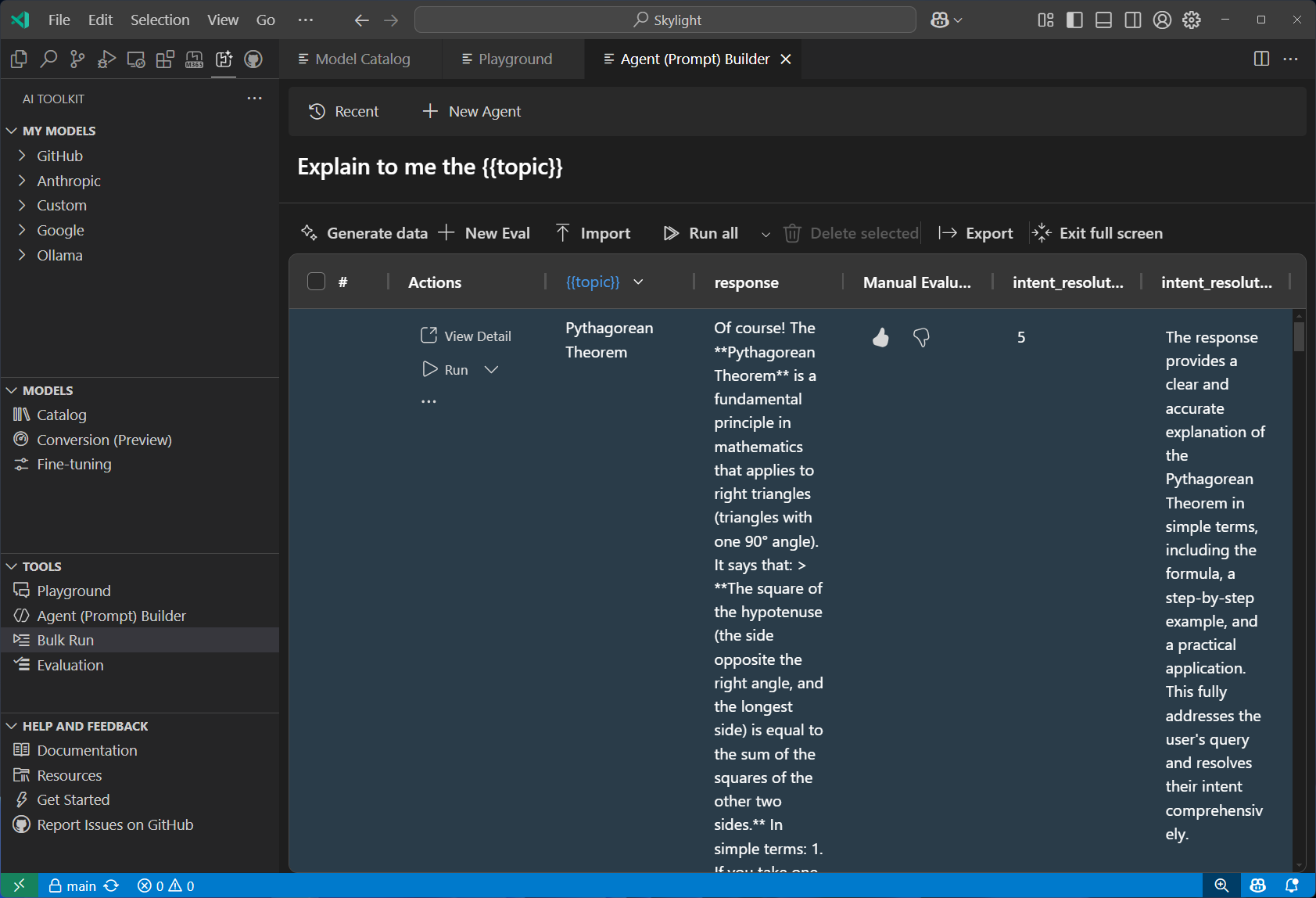
Evaluate an AI model with a dataset 데이터셋과 표준 메트릭을 활용한 포괄적인 모델 평가를 제공함. 내장된 평가 도구(F1 점수, 연관성, 유사도, 일관성 등)를 사용하거나, 사용자 정의 평가 기준을 생성하여 성능을 측정할 수 있음. 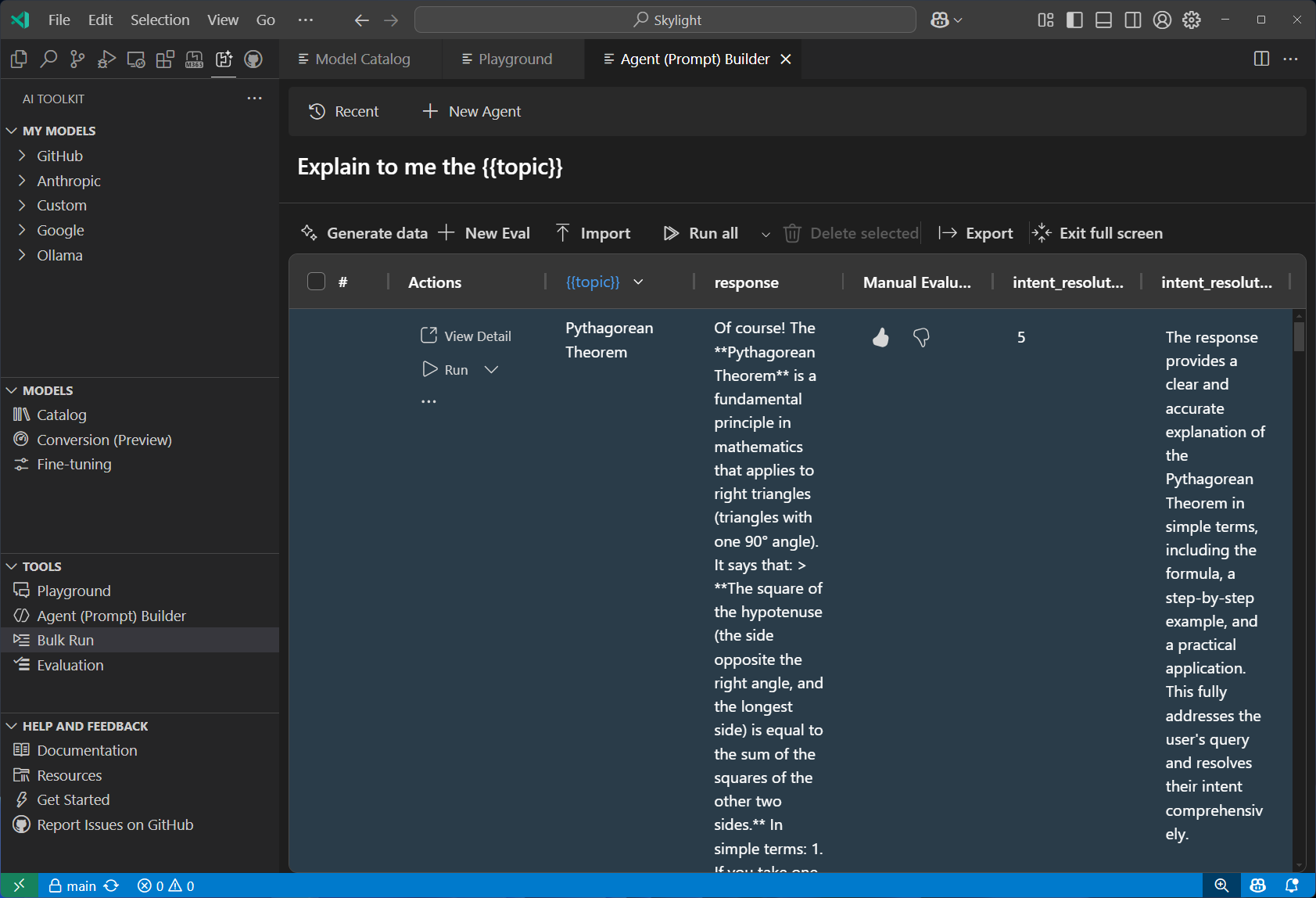
Fine-tuning 특정 도메인과 요구사항에 맞게 모델을 맞춤화하고 최적화할 수 있음. 로컬에서 GPU를 활용해 모델을 학습하거나, Azure Container Apps를 이용해 클라우드 기반의 파인튜닝을 수행할 수 있음 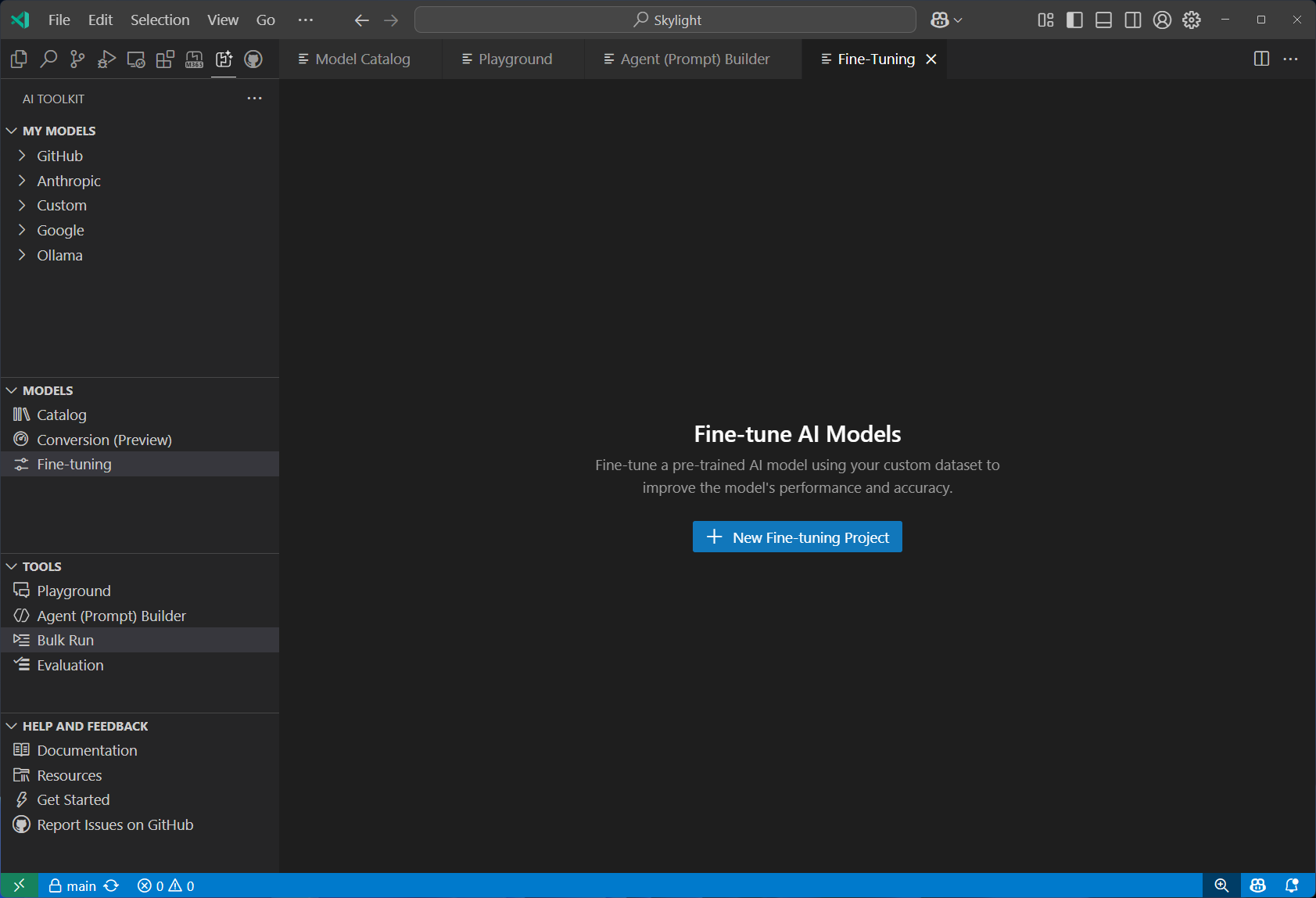
Model Conversion 머신러닝 모델을 로컬 배포용으로 변환, 양자화(quantize), 최적화할 수 있음. Hugging Face 및 기타 소스의 모델을 변환하여 Windows 환경에서 CPU, GPU, 또는 NPU 가속을 활용해 효율적으로 실행할 수 있음. 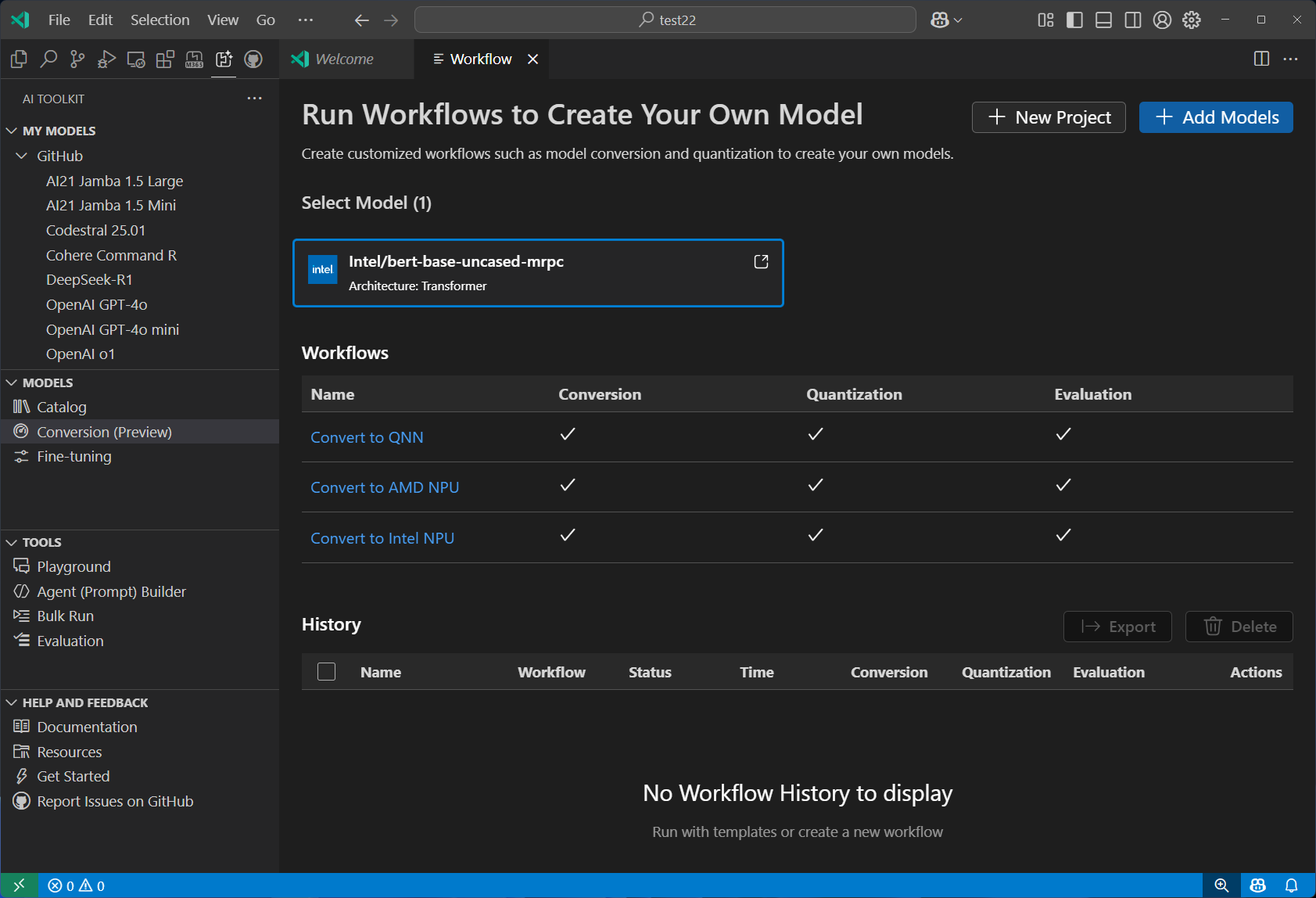
2. AI Toolkit 설치 및 모델 카탈로그 살펴보기
-
AI Toolkit 을 설치하려면, 먼저 Visual Studio Code 가 설치되어 있어야 한다.
-
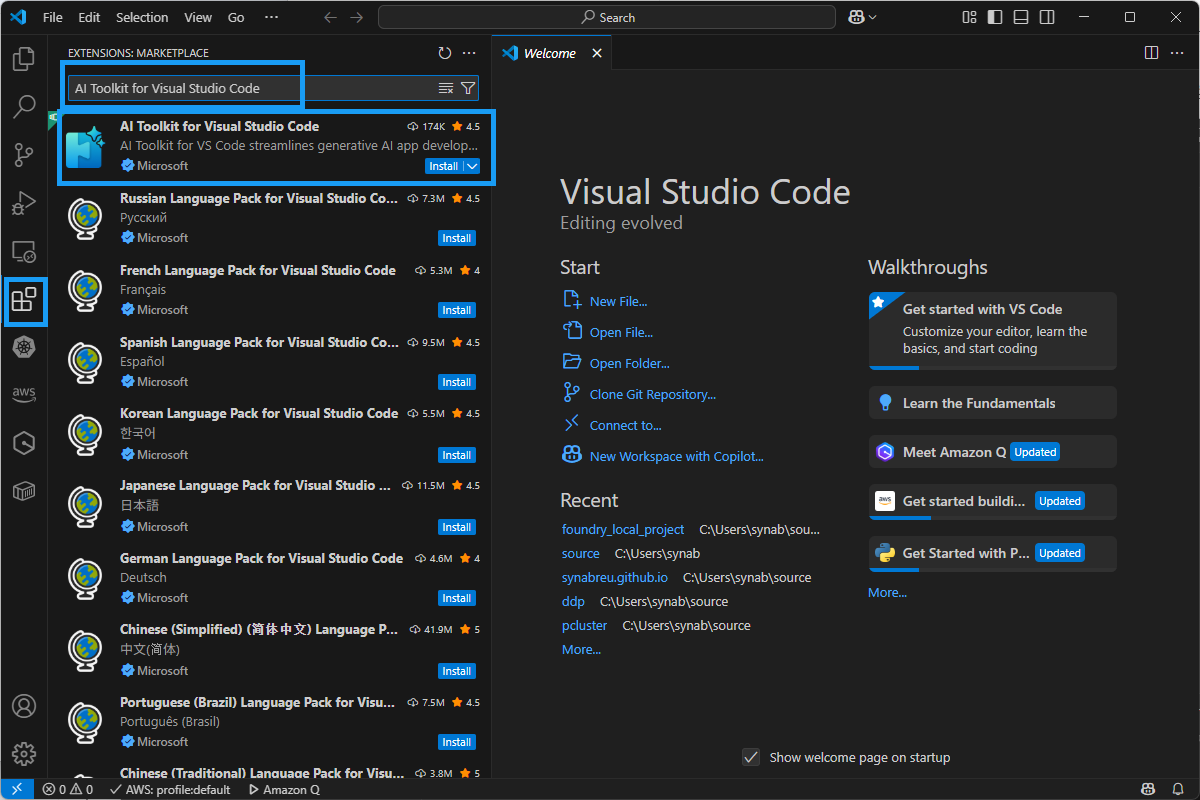
Extentions아이콘을 누른 후, 검색 창에서AI Toolkit for Visual Studio Code를 입력해서 찾은 후에Install버튼을 눌러 설치한다.
-
설치가 끝나면, 아래와 같이 Welcome to AI Toolkit! 화면이 나온다.
Explore AI models라디오 버튼을 누르고,Open Model Catalog버튼을 클릭한다.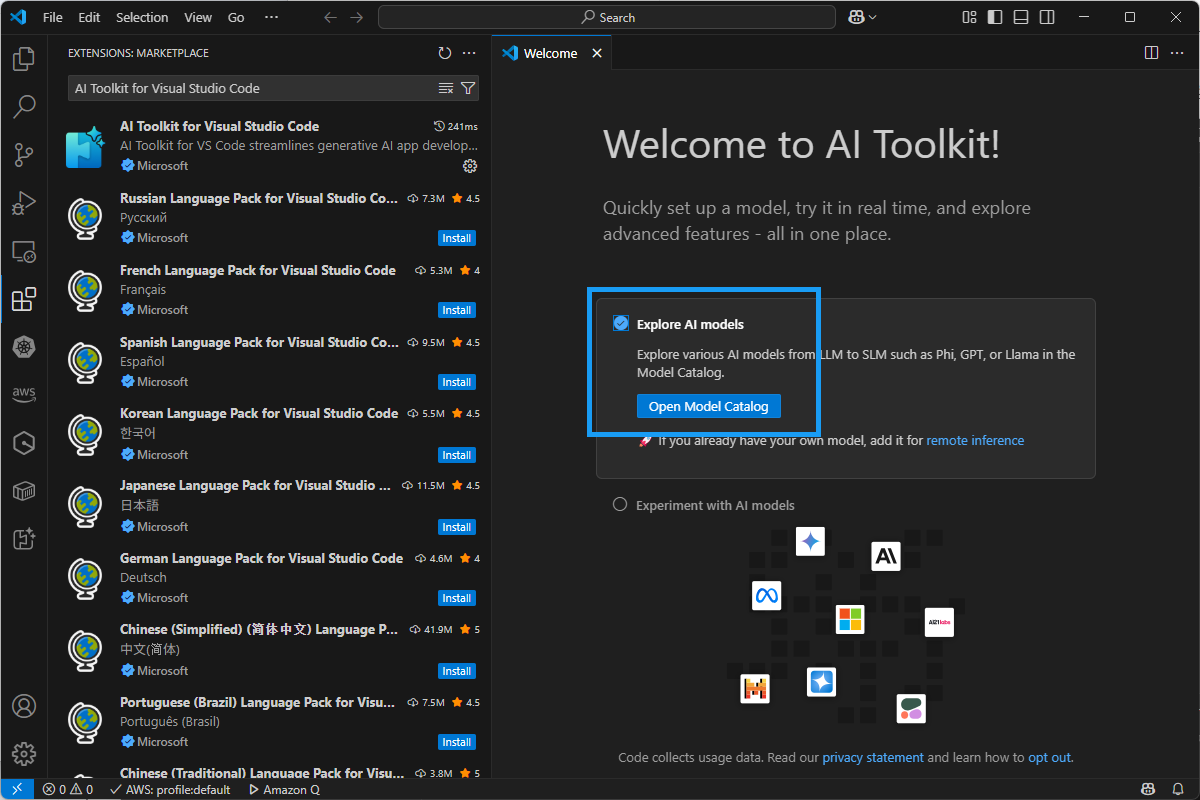
-
그러면, 이제 AI Toolkit에서 지원한 모델 카탈로그가 나타난다. Popular Models 과 GitHub Models, ONNX Models 카탈로그 섹션 등에서 다양한 모델들이 나타난다. 대표적인 모델은 아래와 같다.
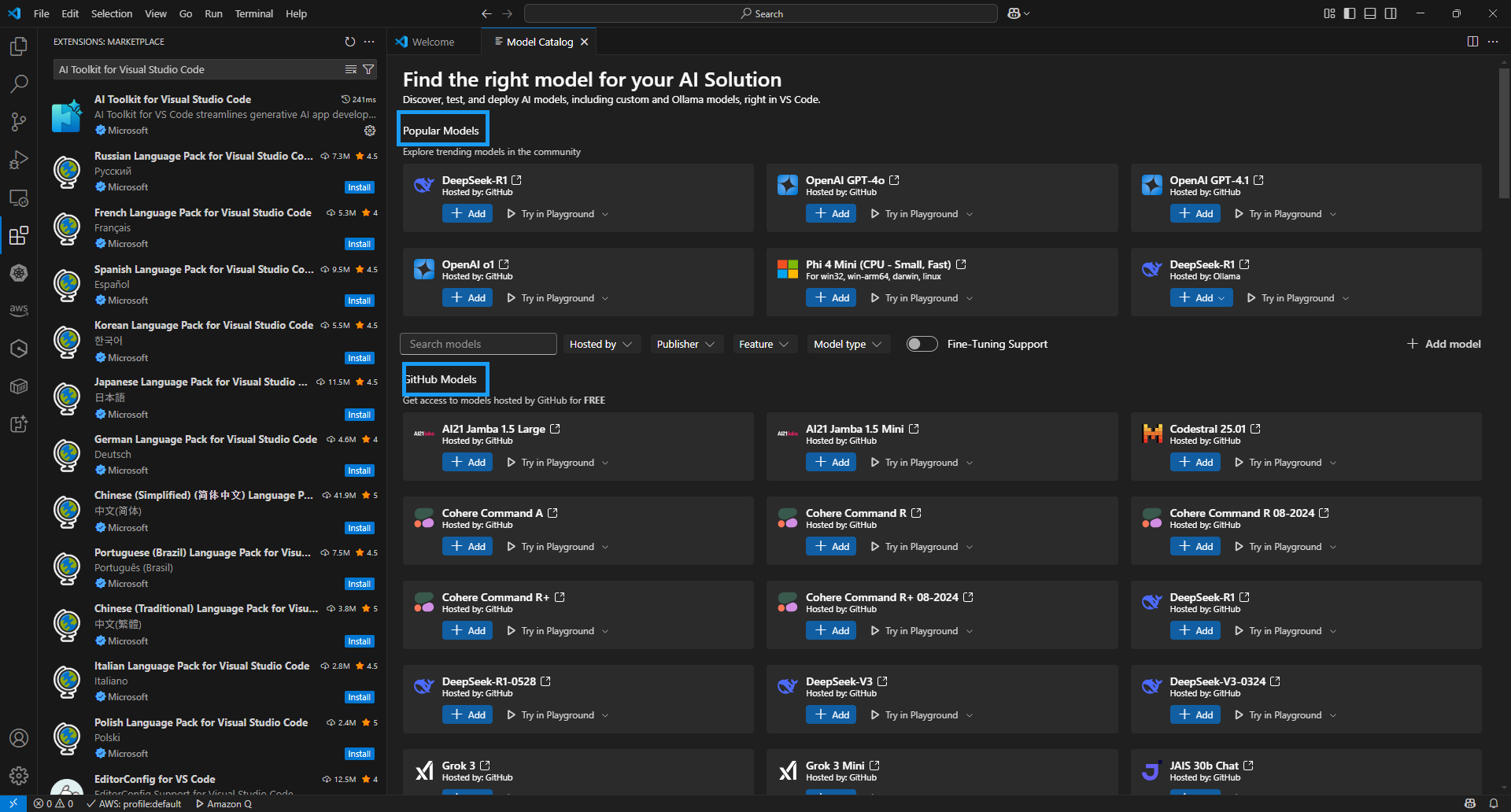
- 참고로 OpenAI GPT-4.1 이나 DeepSeek-R1, Phi 4 Mini (CPU - Small, Fast) 과 같은 인기 있는 모델과, GitHub에서 마련한 Llama 4, Mistral, AI21, Cohere, Grok3 과 같은 모델, 그리고 아래로 내려 가면, Ollama 에서 제공하는 모델과 ONNX 모델 등 다양한 모델드을 지원한다. 심지어 Claude 모델이나 Gemini 와 같은 모델도 다운로드해서 사용할 수 있다.
-
Github 모델 카탈로그과 같은 경우, 모델 카드의 필터를 선택하면 해당 모델의 자세한 정보를 아래와 같이 확인할 수 있다.
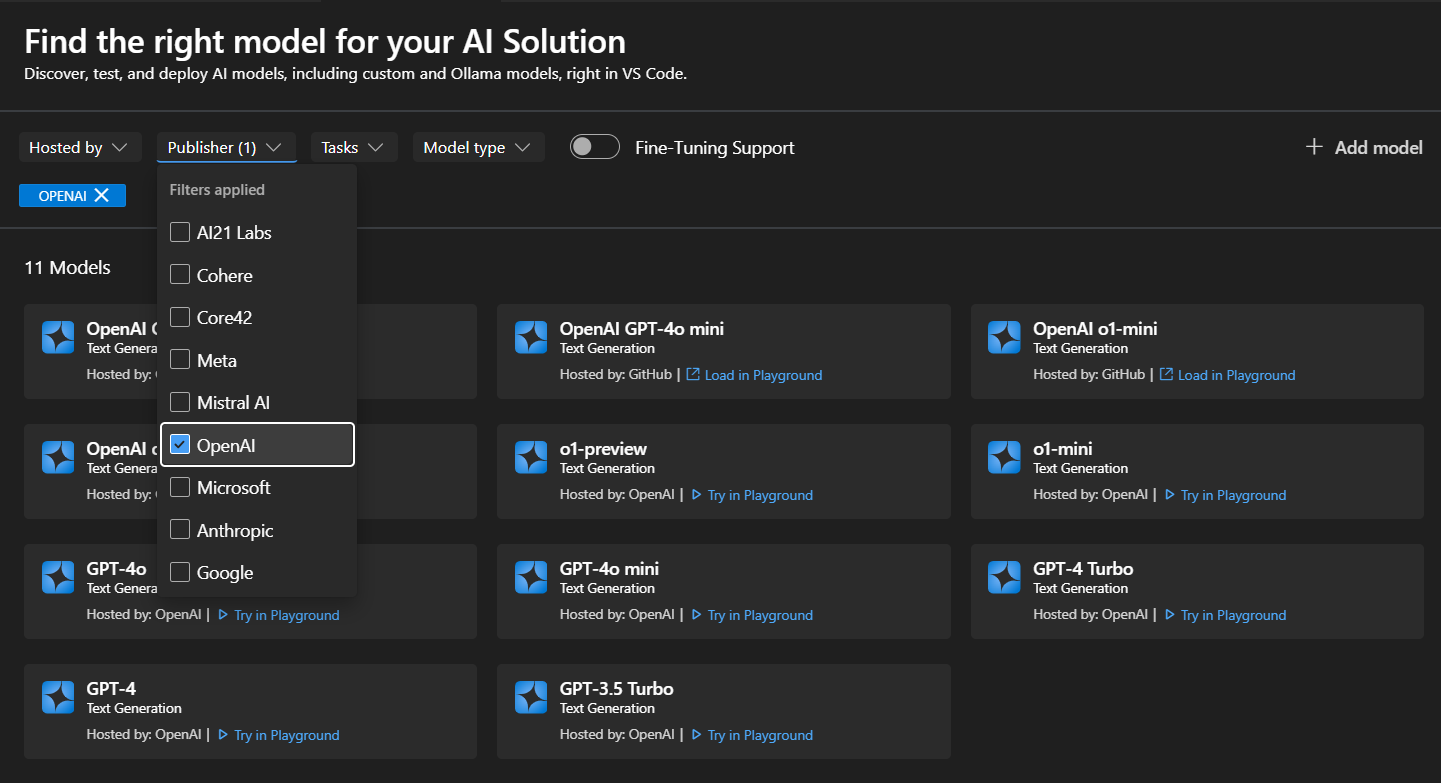
- 검색할 수 있는 필터는?
- 호스팅 위치 (Hosted by): AI Toolkit은 GitHub, ONNX, OpenAI, Anthropic, Google 등의 모델 호스팅 소스를 지원함
- 퍼블리셔 (Publisher): Microsoft, Meta, Google, OpenAI, Anthropic, Mistral AI 등 다양한 퍼블리셔가 제공하는 AI 모델을 확인할 수 있음
- 작업 유형 (Tasks): 현재는 텍스트 생성(Text Generation)만 지원함
- 모델 유형 (Model type): 원격 또는 로컬(CPU, GPU, NPU)에서 실행 가능한 모델을 필터링하며, 이 필터는 로컬 장치의 실행 가능 여부에 따라 달라짐.
- 파인튜닝 지원 (Fine-tuning Support): 파인튜닝 실행이 가능한 모델만 표시함
- 검색할 수 있는 필터는?
3. 모델 플레이그라운드
-
처음 LLM 기반 챗봇 애플리케이션을 개발할 때, 이 플레이그레이드를 이용한다. 만일 플레이그라운드를 사용하려면, 먼저 모델을 다운로드해야 한다. 모델 다운로드는 간단하게
Add버튼을 눌러 모델을 로컬 PC에서 다운로드 실행할 수 있다. 또한, 아래와 같이 모델에 대해 상세한 카탈로그 정보를 보려면 사각형을 누르면 된다.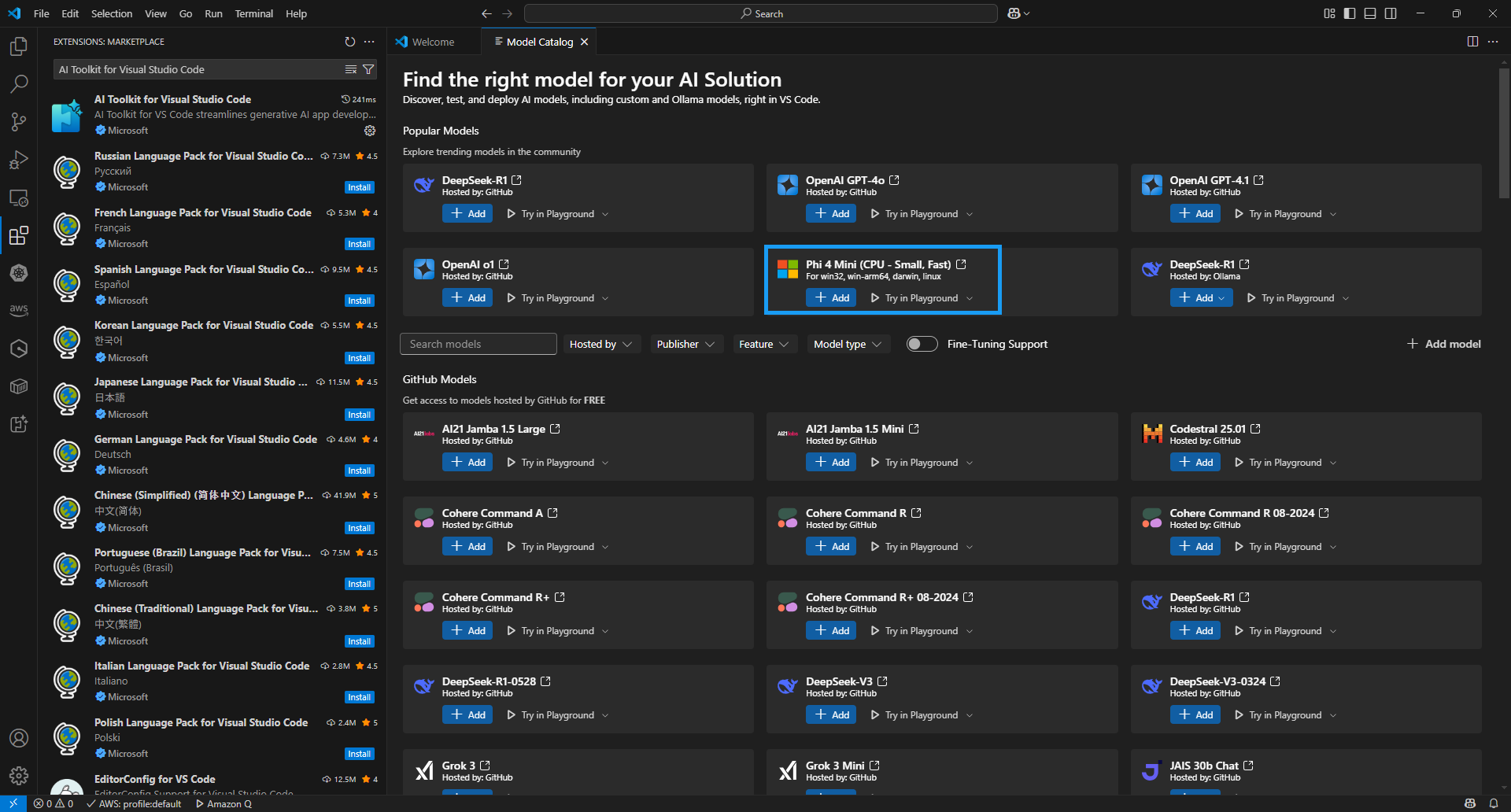
-
사각형을 누른 후, 아래의 그림과 같이 Phi-4-Mini-instruct ONNX models 를 다운로드 하는 상태를 보여주는 화면이다. 모델 카탈로그는 모델의 간단한 정보와 모델 실행(Model Run)은 어떻게 하는 지, 또한 CPU 와 GPU 버전 지원에 따라 실행시킬 수 있도록 정보를 제공해 준다.
-
Phi-4-Mini-instruct ONNX 모델을 다운로드 완료하면, 플레이그라운드를 아래와 같이 사용할 수 있도록 자동적으로 넘어간다.
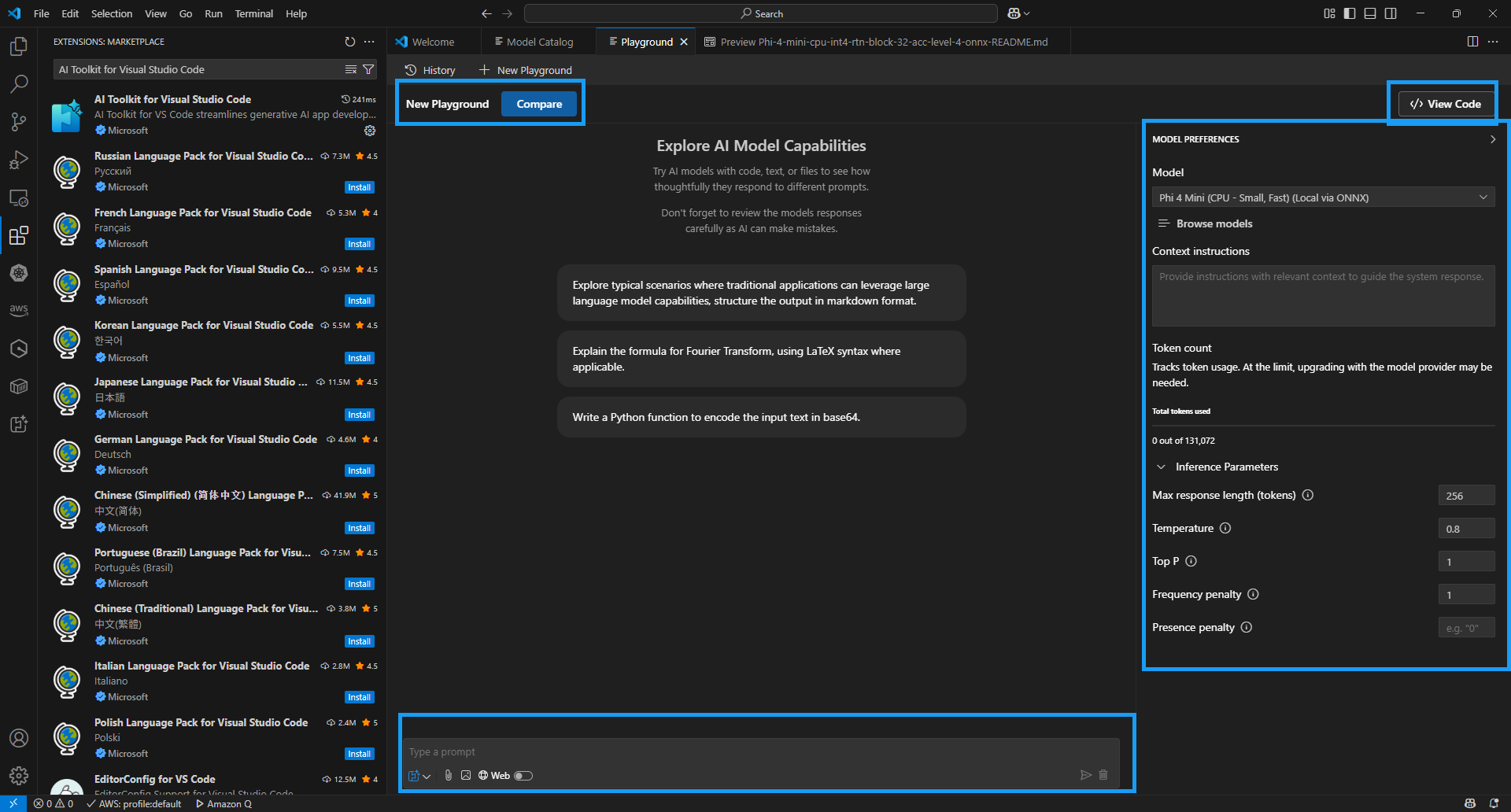
-
New Playground: 새로운 플레이그라운드 생성
-
Compare: 다운로드한 여러 개의 모델들을 비교할 수 있도록 제공
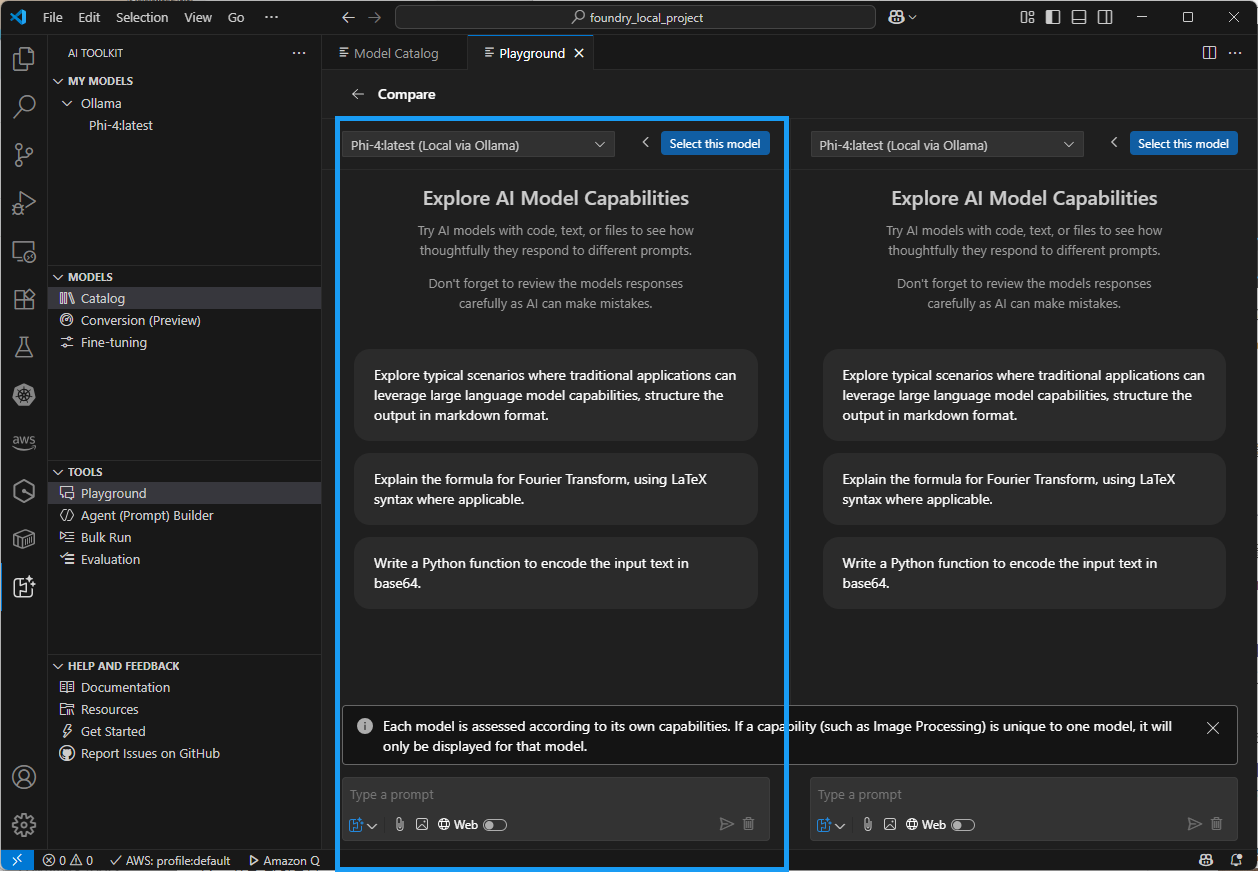
-
Chatting WIndow: 아래에 사용자 프롬프트 명령(대화)를 할 수 있는 윈도우
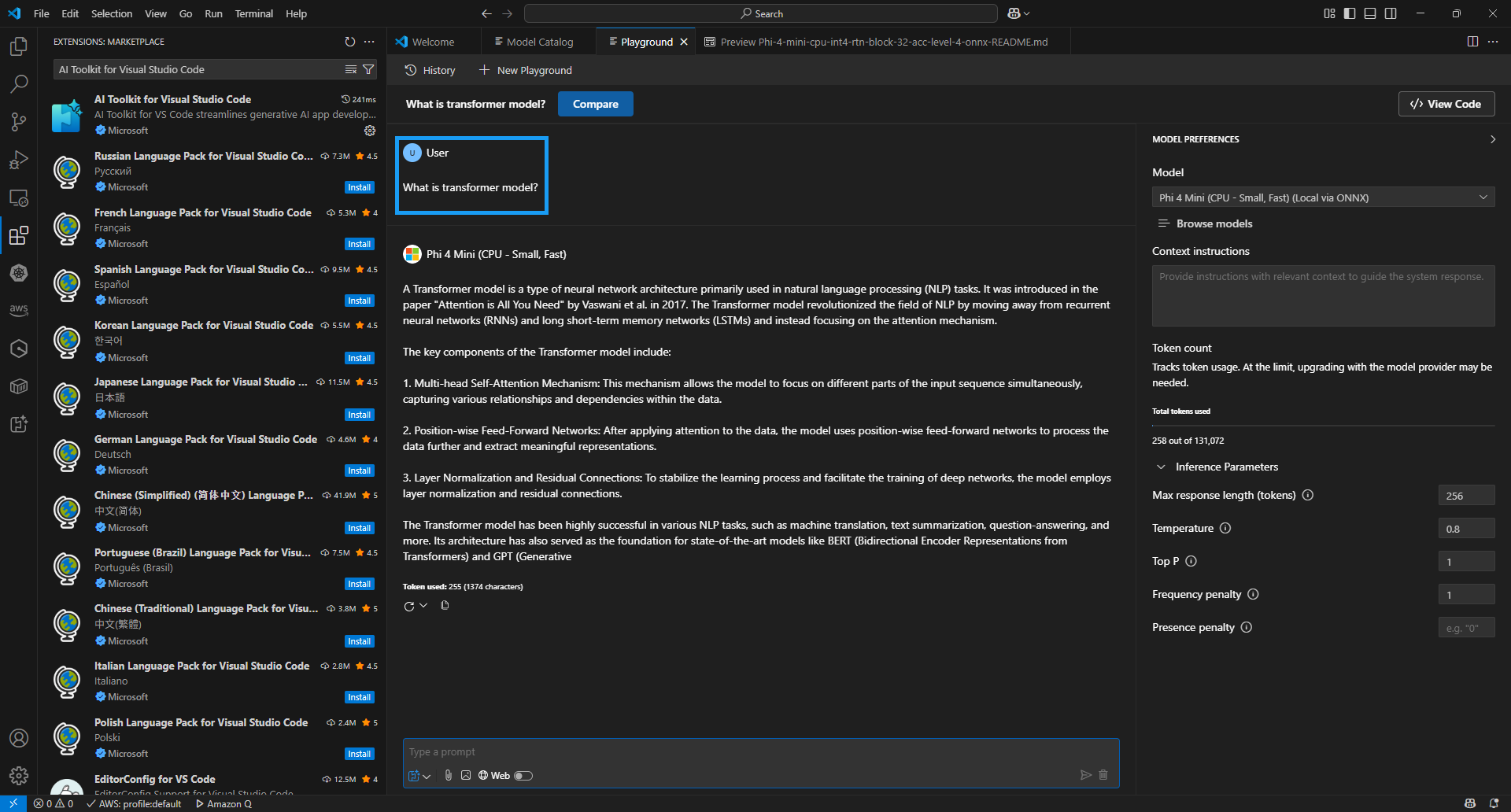
-
View Code: 지금까지 설정한 내용을 바탕으로 파이썬 코드를 생성해 줌
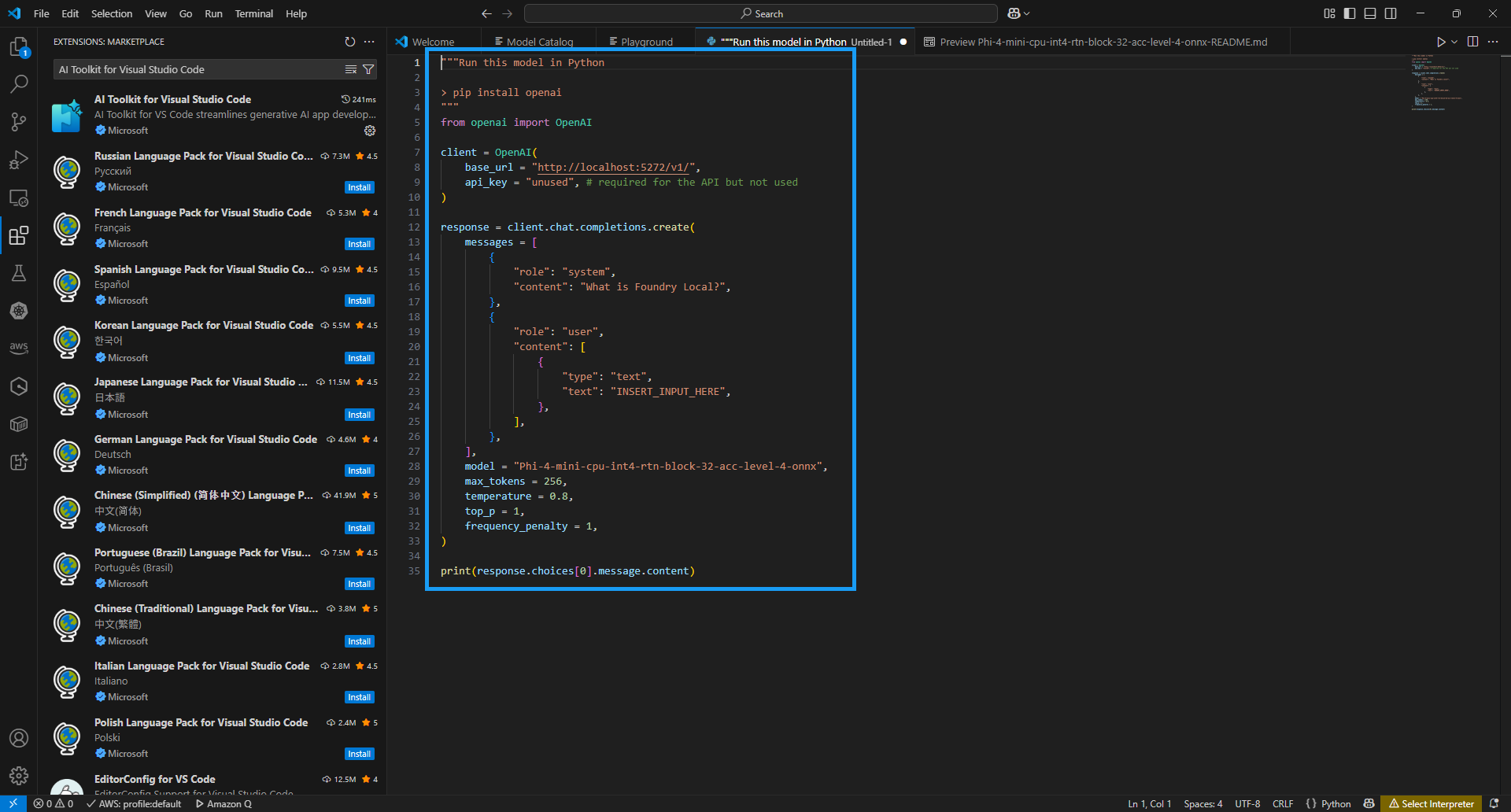
-
로컬PC의 모델 다운로드 위치
-
아래의 보듯이 탐색기를 통해
C:\Users\<사용자명>\.foundry\cache\models\Microsoft\폴더에 가면, 현재 내가 다운로드 받은 모델 리스트를 볼 수 있다.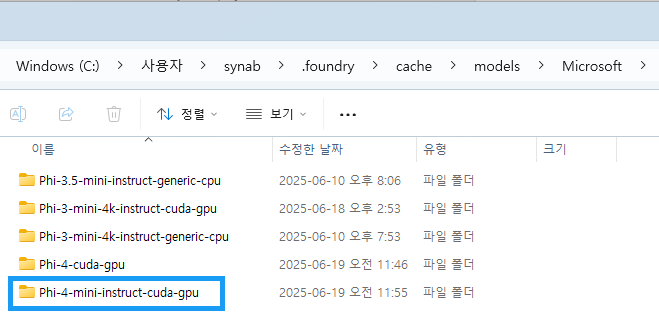
-
Phi-4-mini-instruct-cuda-gpu와 같은경우,model.onnx.data파일이 약 3.7 기가정도 되는 것을 확인할 수 있다. 그 외 token 과 inference 관련 정보들에 관해 포함되어 있다.
-

-
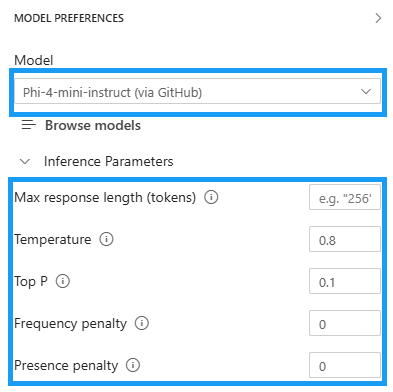
Model Preferences
-
Model: 현재 로컬로 다운로드한 모델
-
Browse Models: 새로운 모델을 검색하고 다운로드 받기 위해 모델 카탈로그 화면 이동
-
Context instructions: system prompt 에 사용할 내용
-
Inference Parameters
- Max response length (tokens): 기본적으로 2,048 개 토큰. 모델이 생성할 수 있는 최대 토큰 수 (단어의 조각). 응답의 길이를 제한하여 처리 시간 또는 비용을 조절함.
- Temperature: 0.8로 조정. 출력의 무작위성(창의성)을 조절하는 값. 값이 낮을수록: 결정적이고 예측 가능한 응답 생성 (정답 위주, 논리적). 값이 높을수록: 창의적이고 다양성 있는 응답 생성 (실험적, 문학적).
- Top P: 0.1로 설정함(모델이 매우 제한된 확률 상위 후보만 사용 → 응답 다양성 낮음, 정확도 높음). 확률 상위 P% 단어들만 고려하여 샘플링하는 방식. 확률 누적합이 P 이하가 될 때까지 후보 단어만 남겨두고 그 안에서 선택하는 방식.
- Frequency penalty: 같은 단어가 반복해서 등장하지 않도록 억제하는 계수. 값이 클수록: 동일 단어가 자주 등장할수록 점수를 깎음 → 반복 줄임.
- Presence penalty: 이미 언급된 단어의 재등장을 억제하여 새로운 주제가 등장할 가능성을 높임.
- Frequency는 빈도수 기반 억제, Presence는 존재 여부 자체에 따른 억제
- 보통
Top P와Temperature는 서로 보완 관계.
-
-
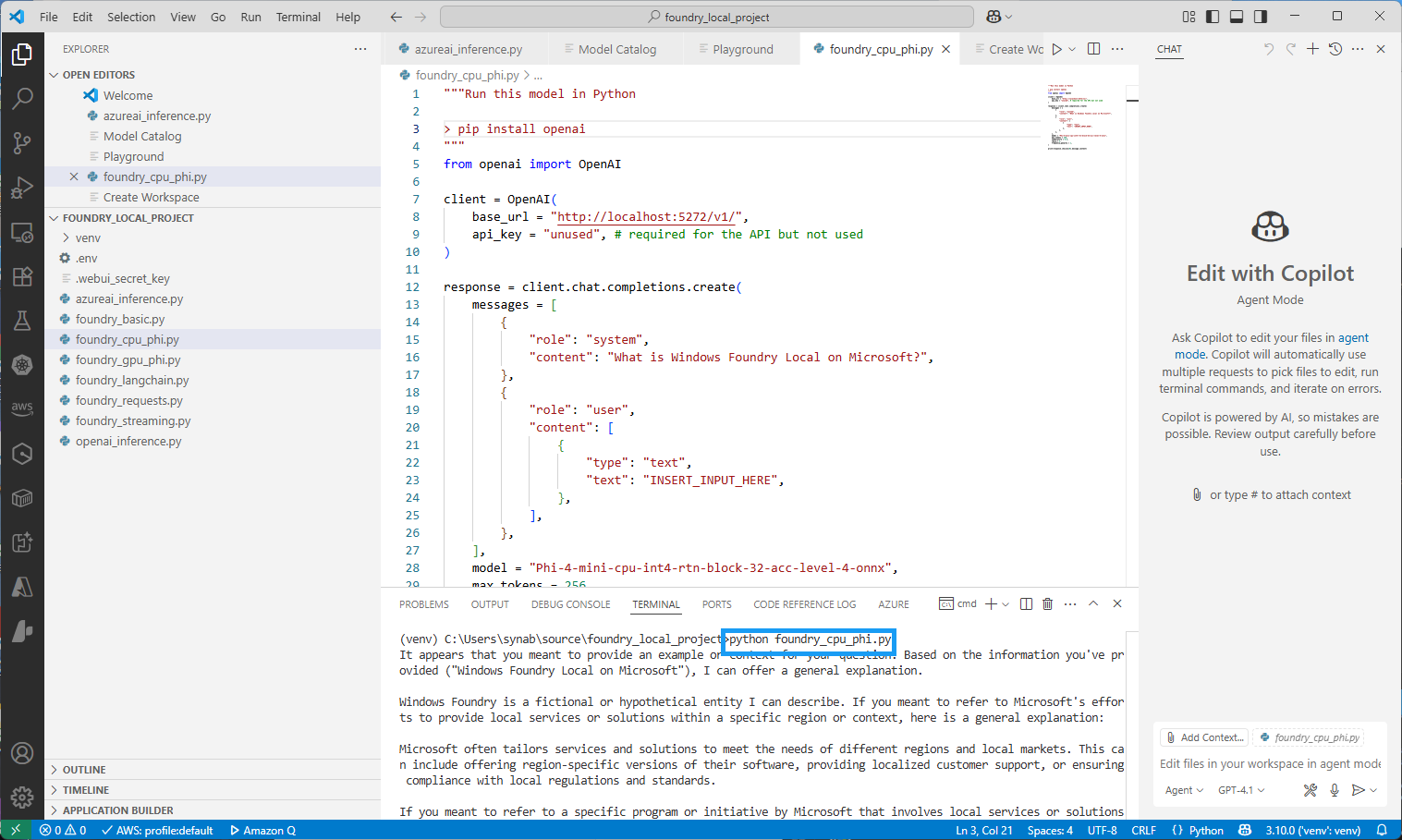
파이썬 소스 코드 실행
-
4. GPU 지원하는 모델 플레이그라운드
-
GPU를 지원하는 모델을 사용하기 위해서는 왼쪽 AI Toolkit 아이콘을 클릭해서 MODELS 섹션에서 Catalog 를 선택하면 모델 카탈로그가 나타난다. 여기에서 검색 필터에서
gpu를 입력하면, 현재 모델들 중에 GPU를 지원하는 모델리스트가 나타난다.
-
GPU를 지원하는 모델 중
Phi 4 Mini (DirectML/CUDA - Small standard)모델을 선택해서 Add 하면 로컬로 다운로드 시작한다.
-
Phi 4 Mini (DirectML/CUDA - Small standard)모델 다운로드 완료하면, Added 라고 녹색으로 표시된다. 그리고 아래를 보시면Try PLayground버튼을 눌러 플레이그라운드를 실행시킬 수 있다.
-
플레이그라운드에서는 사용자 프롬프트를 이용해서 모델을 테스트하거나, 다양한 모델 추론 파라미터를 조정해서 사용할 수 있다. GPU를 이용하면 CPU를 사용할 떄 훨씬 빠른 실행할 수 있다.
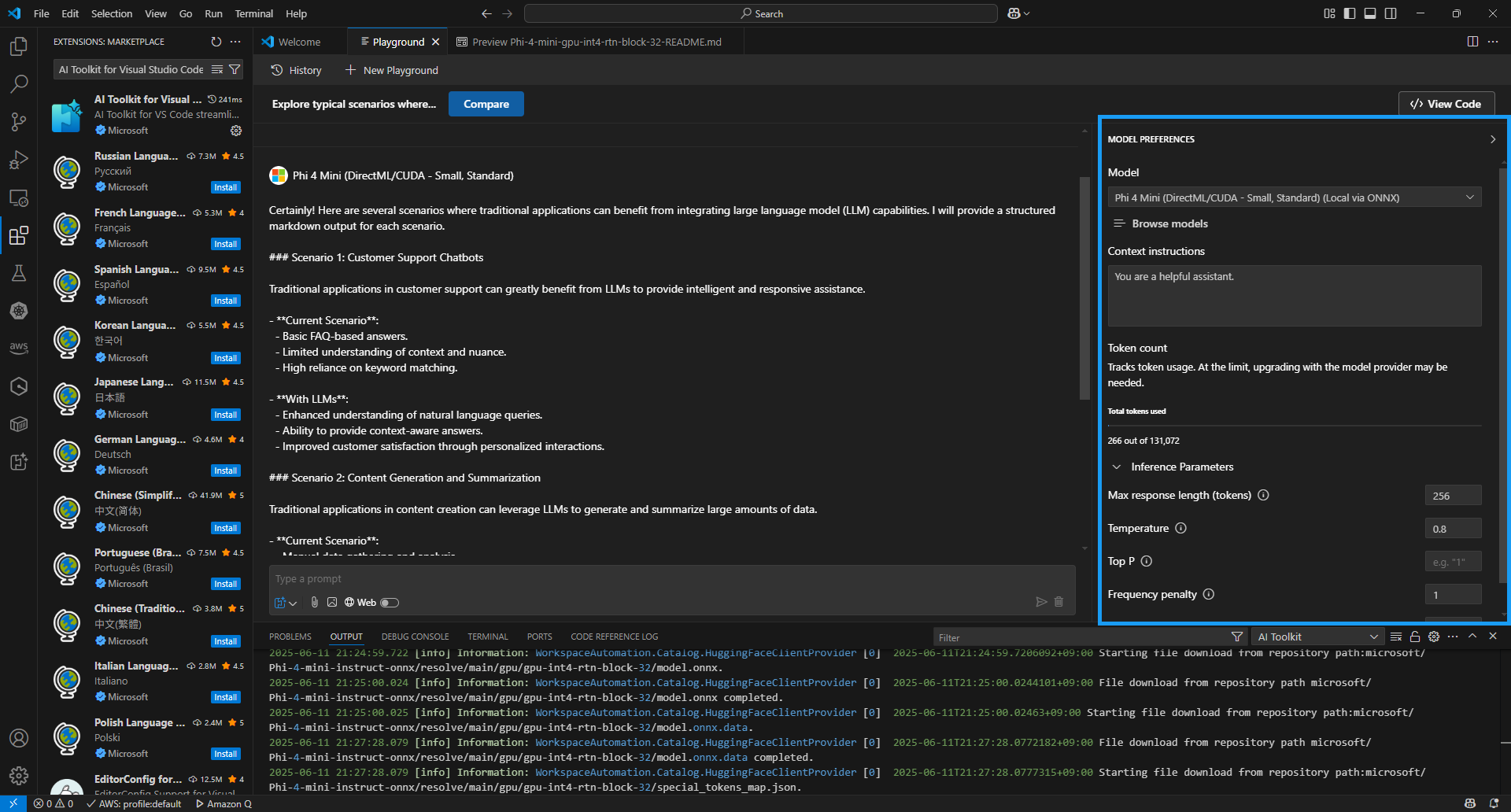
-
모델 카탈로그에서
View Code를 누르면, 지금까지 파라미터를 설정한 근거를 바탕으로 파이썬 코드를 생성한다. 이를 파이썬으로 실행하면 아래와 같은 결과가 나타난다.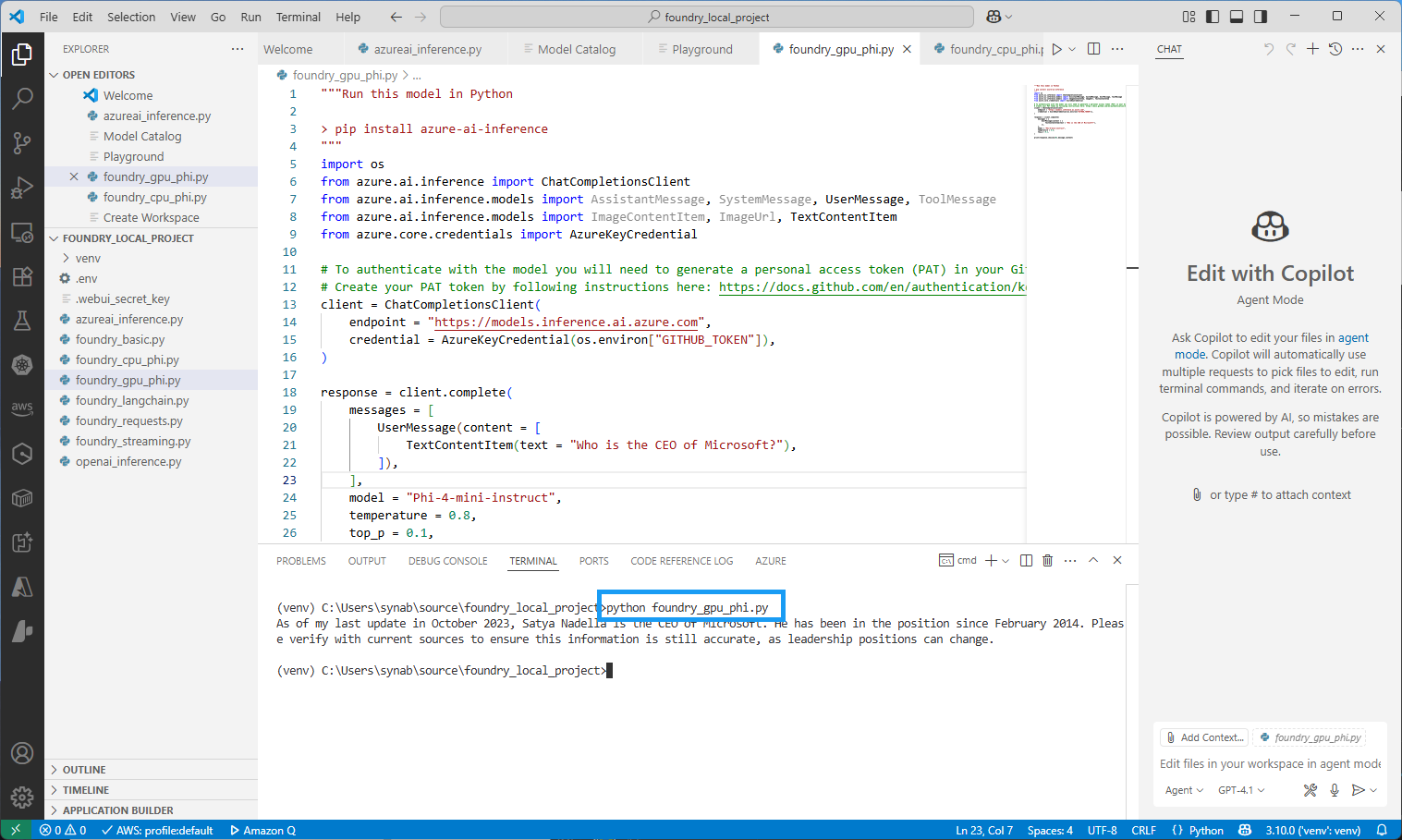
댓글남기기