[실습] 파운드리 로컬에서 OpenAI SDK 사용하기
이제 파운드리 로컬을 사용해서 본격적으로 파이썬 프로그래밍을 한 번 해보자! 내 노트북에서 phi-3-mini-4k 모델을 다운로드했기 때문에 기본적인 OpenAI SDK를 사용해서 모델 추론하는 예와, Stream Response 과 Requests 라이브러리를 사용하는 방법에 대해 정리해 보았다.
1. OpenAI SDK 를 사용해서 모델 추론
-
목표: Foundry Local에서 OpenAI SDK를 사용하는 방법은 Foundry Local 서비스를 초기화하고, 모델을 로드한 다음, OpenAI SDK를 사용하여 응답을 생성한다.
-
Visual Studio Code를 실행 한 후, 프로젝트를 하나 만들어서 파일을 만든다. 예를 들어, 저와 같은 경우에는 프로젝트 이름은
Foundry_Local_Project와 파일 명은foundry_basic.py이다.
-
프로젝트마다 필요한 라이브러리 버전이 다를 수 있기 때문에, 전역 Python 환경과 격리된 독립적인 패키지 공간이 생기므로 그러한 버전 충돌을 방지하기 위해 다음과 같이 명령어를 실행해서 가상 환경을 생성함
python -m venv venv .\venv\Scripts\Activate -
foundry_basic.py소스 파일을 컴파일하기 위해서는 다음과 같은 라이브러리를 먼저 설치해야 한다.pip install openai pip install foundry-local-sdk pip install foundry_local -
파이썬 소스 설명은 다음과 같다.
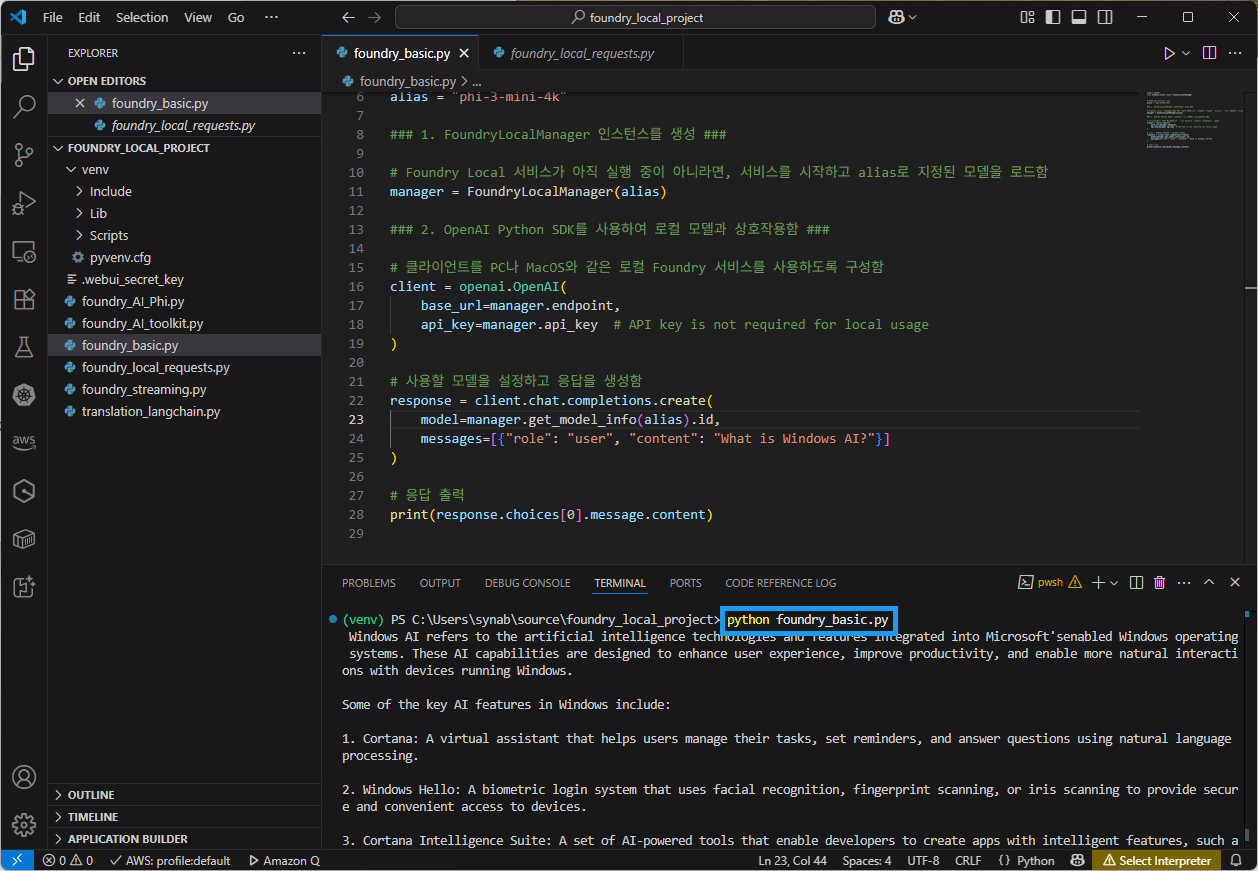
import openai from foundry_local import FoundryLocalManager # 모델 별칭(alias) 사용 alias = "phi-3-mini-4k" ### 1. FoundryLocalManager 인스턴스를 생성 ### # Foundry Local 서비스가 아직 실행 중이 아니라면, 서비스를 시작하고 alias로 지정된 모델을 로드함 manager = FoundryLocalManager(alias) ### 2. OpenAI Python SDK를 사용하여 로컬 모델과 상호작용함 ### # 클라이언트를 PC나 MacOS와 같은 로컬 Foundry 서비스를 사용하도록 구성함 client = openai.OpenAI( base_url=manager.endpoint, api_key=manager.api_key # 로컬에서 사용할 경우 API 키는 필요하지 않음. ) # 사용할 모델을 설정하고 응답을 생성함 response = client.chat.completions.create( model=manager.get_model_info(alias).id, messages=[{"role": "user", "content": "What is Windows AI?"}] ) # 응답 출력 print(response.choices[0].message.content) -
실행 후 다음과 같은 결과 화면이 출력한다.
2. Stream Response 사용 예
-
스트리밍 응답(Stream Response)는 AI 모델 또는 API 서버가 생성한 결과를 한 번에 전송하는 것이 아니라, 생성되는 즉시 토막 단위(예: 토큰, 문자열)로 나눠서 순차적으로 전송하는 방식
-
Stream Response 사용 유무는
stream=True로 설정하면, 사용자 경험(UX)을 중시하는 앱이나 채팅형 UI에서 유리하고,stream=False는 코드가 간단하며 작은 요청이나 일괄 처리용 스크립트에 적합하다. -
Stream 비교 요약
항목 stream=Truestream=False응답 시점 토큰 단위 실시간 반환 전체 완료 후 한 번에 반환 사용자 경험 빠른 피드백, 반응 빠름 전체 내용이 한꺼번에 나옴 구현 복잡도 조금 복잡 (루프 처리 필요) 간단함 메모리 사용 적음 (조각 처리) 많을 수 있음 (전체 보관 필요) 용도 채팅, 터미널 UI, 스트리밍 앱 API 연동, 간단한 스크립트 -
스트리밍 응답(
stream=True)-
특징
- 모델 응답이 생성되는 대로 즉시 전달됨 (토큰 단위 또는 문장 단위)
- 사용자 입장에서는 “한 글자씩 실시간으로 나오는 느낌”을 받음
- 긴 응답을 기다리지 않고 빠르게 출력이 시작됨
- UI/UX에 민감한 애플리케이션(예: Chatbot, 터미널 CLI 등)에 매우 유리
-
예시
W Wh Wha What What is ... -
장점
- 응답을 빠르게 전달하여 즉시 피드백 제공
- 터미널/웹 UI 등에서 입력 반응 속도가 빠름
- 대용량 응답 처리 시 메모리 부담이 적음 (조각별로 처리 가능)
-
-
스트리밍 응답 생략 - 기본값(
stream=False)-
특징
- 전체 응답이 모델 측에서 모두 생성 완료된 뒤 한꺼번에 반환됨
- 사용자는 완성된 결과를 한 번에 받게 됨
-
예시
(응답 없음)... 몇 초 뒤 → What is Microsoft Foundry Local? It is a local AI inference engine ... -
장점
- 처리 흐름이 단순하여 코딩하기 쉽고 디버깅하기 좋음
- 응답이 짧고 간단할 경우 성능 차이는 거의 없음
-
-
사용 사례
- 채팅 애플리케이션 (Chatbot) → 사용자에게 “실시간 대화 느낌” 제공
- 터미널 기반 CLI → 점진적으로 결과 확인 가능
- 웹 기반 UI → 글자 단위로 보여주며 긴 응답도 빠르게 처리 가능
-
foundry_streaming.py 예제 소스
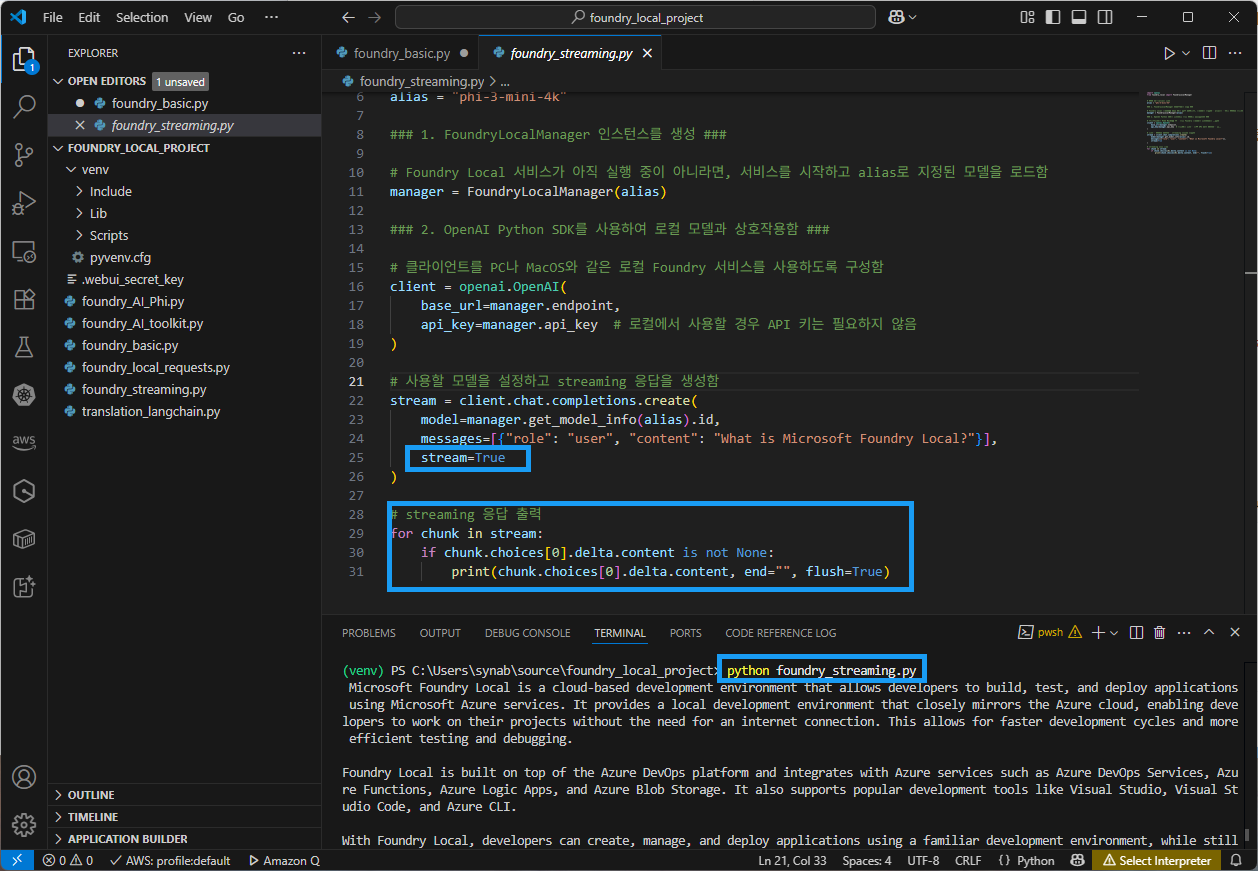
import openai from foundry_local import FoundryLocalManager # 모델 별칭(alias) 사용 alias = "phi-3-mini-4k" ### 1. FoundryLocalManager 인스턴스를 생성 ### # Foundry Local 서비스가 아직 실행 중이 아니라면, 서비스를 시작하고 alias로 지정된 모델을 로드함 manager = FoundryLocalManager(alias) ### 2. OpenAI Python SDK를 사용하여 로컬 모델과 상호작용함 ### # 클라이언트를 PC나 MacOS와 같은 로컬 Foundry 서비스를 사용하도록 구성함 client = openai.OpenAI( base_url=manager.endpoint, api_key=manager.api_key # 로컬에서 사용할 경우 API 키는 필요하지 않음 ) # 사용할 모델을 설정하고 streaming 응답을 생성함 stream = client.chat.completions.create( model=manager.get_model_info(alias).id, messages=[{"role": "user", "content": "What is Microsoft Foundry Local?"}], stream=True ) # streaming 응답 출력 for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) -
실행 결과
3. Requests 라이브러리 사용
-
목적
Foundry Local에서requests라이브러리를 사용하는 경우, HTTP 기반 직접 호출 방식으로 로컬 모델과 통신할 때 사용함- Foundry Local은 OpenAI SDK뿐만 아니라 HTTP REST API 형식도 지원하기 때문에,
requests라이브러리를 이용해 직접 모델에 요청(request)을 보낼 수 있음
-
동작
requests를 사용하면 Foundry Local이 실행 중인 엔드포인트(예:http://localhost:8080/v1/chat/completions)에 POST 요청을 보내서 모델에게 프롬프트를 전달하고, 응답을 직접 받아올 수 있음
-
foundry_requests.py 예제 소스
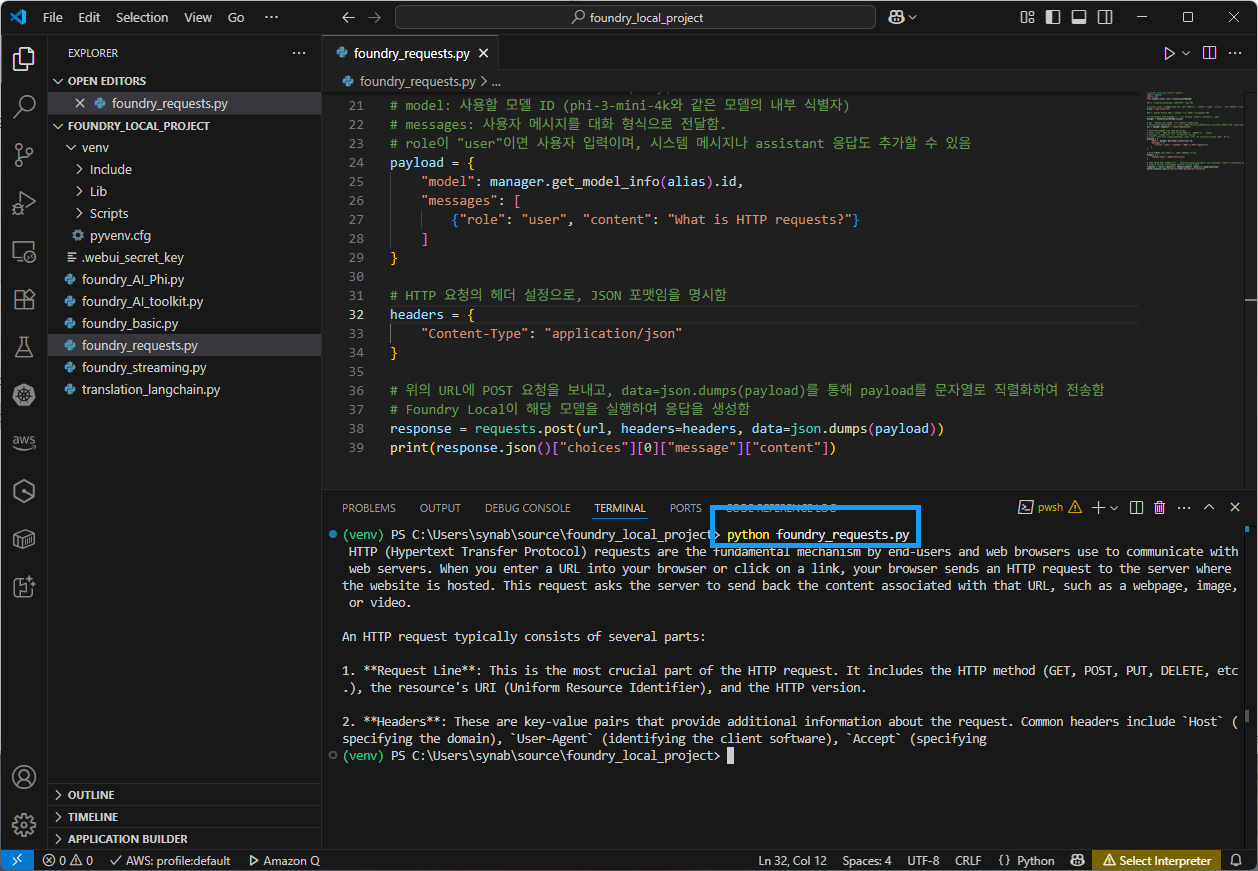
# requests 라이브러리 설치(pip install requests) import requests import json from foundry_local import FoundryLocalManager ### 1. FoundryLocalManager 인스턴스를 생성 ### # Foundry Local 서비스가 아직 실행 중이 아니라면, 서비스를 시작하고 alias로 지정된 모델을 로드함 alias = "phi-3-mini-4k" ### 2. OpenAI Python SDK를 사용하여 로컬 모델과 상호작용함 ### # 클라이언트를 PC나 MacOS와 같은 로컬 Foundry 서비스를 사용하도록 구성함 manager = FoundryLocalManager(alias) # URL은 OpenAI Chat API와 유사한 RESTful 인터페이스 # FoundryLocalManager에서 얻은 로컬 서버의 API 엔드포인트(http://localhost:8080 등)에 /chat/completions 경로를 붙여서 대화형 모델 호출 URL을 완성함 url = manager.endpoint + "/chat/completions" # HTTP POST 요청에 담을 JSON 본문(body) # model: 사용할 모델 ID (phi-3-mini-4k와 같은 모델의 내부 식별자) # messages: 사용자 메시지를 대화 형식으로 전달함. # role이 "user"이면 사용자 입력이며, 시스템 메시지나 assistant 응답도 추가할 수 있음 payload = { "model": manager.get_model_info(alias).id, "messages": [ {"role": "user", "content": "What is HTTP requests?"} ] } # HTTP 요청의 헤더 설정으로, JSON 포맷임을 명시함 headers = { "Content-Type": "application/json" } # 위의 URL에 POST 요청을 보내고, data=json.dumps(payload)를 통해 payload를 문자열로 직렬화하여 전송함 # Foundry Local이 해당 모델을 실행하여 응답을 생성함 response = requests.post(url, headers=headers, data=json.dumps(payload)) print(response.json()["choices"][0]["message"]["content"]) -
foundry_requests.py 파일을 실행하기 위해서는 먼저 requests 라이브러리를 설치해야 함
pip install requests -
실행 결과
4. 예제 소스 코드
- 깃허브 예제 소스 코드
댓글남기기