마이크로소프트 파운드리 로컬(Foundry Local)에 대하여
지난 마이크로소프트 빌드 2025에서 발표한 마이크로소프트 파운드리 로컬(Microsoft Foundry Local)의 개념과 주요 특징, 서비스 아키텍처, 그리고 개발자 도구 지원에 정리해 보았다.
1. 파운드리 로컬(Foundry Local)은 무엇인가?
- PC 또는 맥의 성능, 프라이버시, 맞춤화, 비용 측면에서 이점을 제공하는 온디바이스 AI 추론 솔루션
- 개발자들에게 직관적인 CLI, SDK, REST API를 통해 기존 워크플로우 및 애플리케이션에 원활하게 통합
- 파운드리 로컬(Foundry Local)은 Azure 구독이 필요하지 않음. 로컬 하드웨어에서 실행되므로, 클라우드 서비스를 사용하지 않고도 기존 인프라를 그대로 활용할 수 있음.
- 파운드리 로컬(Foundry Local)은 현재 프리뷰(preview) 버전으로 제공하고 있으며, 퍼블릭 프리뷰 릴리스를 통해 배포 중인 기능들을 조기에 체험할 수 있음. 일반 공개(GA) 전에 기능, 접근 방식, 프로세스는 변경되거나 제한된 기능만 제공함
2. 파운드리 로컬(Foundry Local)주요 특징
- 온-디바이스(On-Device) 추론: 모델을 로컬 하드웨어에서 실행해 비용을 절감하고 모든 데이터를 장치 내에 안전하게 유지함. 다시 말해, 데이터를 외부로 보내지 않고, 기기 내에서 AI 모델을 실행하는 기술
- 모델 맞춤화: 사전 설정된 모델을 선택하거나 자체 모델을 사용하여 특정 요구사항과 사용 사례에 맞게 구성할 수 있음.
- 비용 효율성: 기존 하드웨어를 활용함으로써 반복적인 클라우드 서비스 비용을 제거하고, AI를 보다 쉽게 활용할 수 있음.
- 원활한 통합: SDK, API 엔드포인트 또는 CLI를 통해 애플리케이션과 손쉽게 연동되며, 필요에 따라 Azure AI Foundry로 손쉽게 확장할 수 있음.
3. 파운드리 로컬(Foundry Local) 장점
- 저지연성(Low Latency): 모델을 로컬에서 실행하여 처리 시간을 최소화하고 더 빠른 결과를 제공함
- 데이터 프라이버시: 민감한 데이터를 클라우드로 전송하지 않고 로컬에서 처리하여 데이터 보호 요구사항을 충족할 수 있음
- 유연성: 다양한 하드웨어 구성을 지원하여 사용자에게 최적의 환경을 선택할 수 있도록 함
- 확장성: 노트북부터 서버까지 다양한 장치에 배포할 수 있어 여러 사용 사례에 적합함
- 비용 효율성: 특히 대규모 애플리케이션에서 클라우드 컴퓨팅 비용을 절감할 수 있음
- 오프라인 작동: 인터넷 연결이 없는 원격지나 단절된 환경에서도 작동할 수 있음
- 원활한 통합: 기존 개발 워크플로우에 쉽게 통합되어 도입이 간편함
4. 파운드리 로컬 서비스 아키텍처
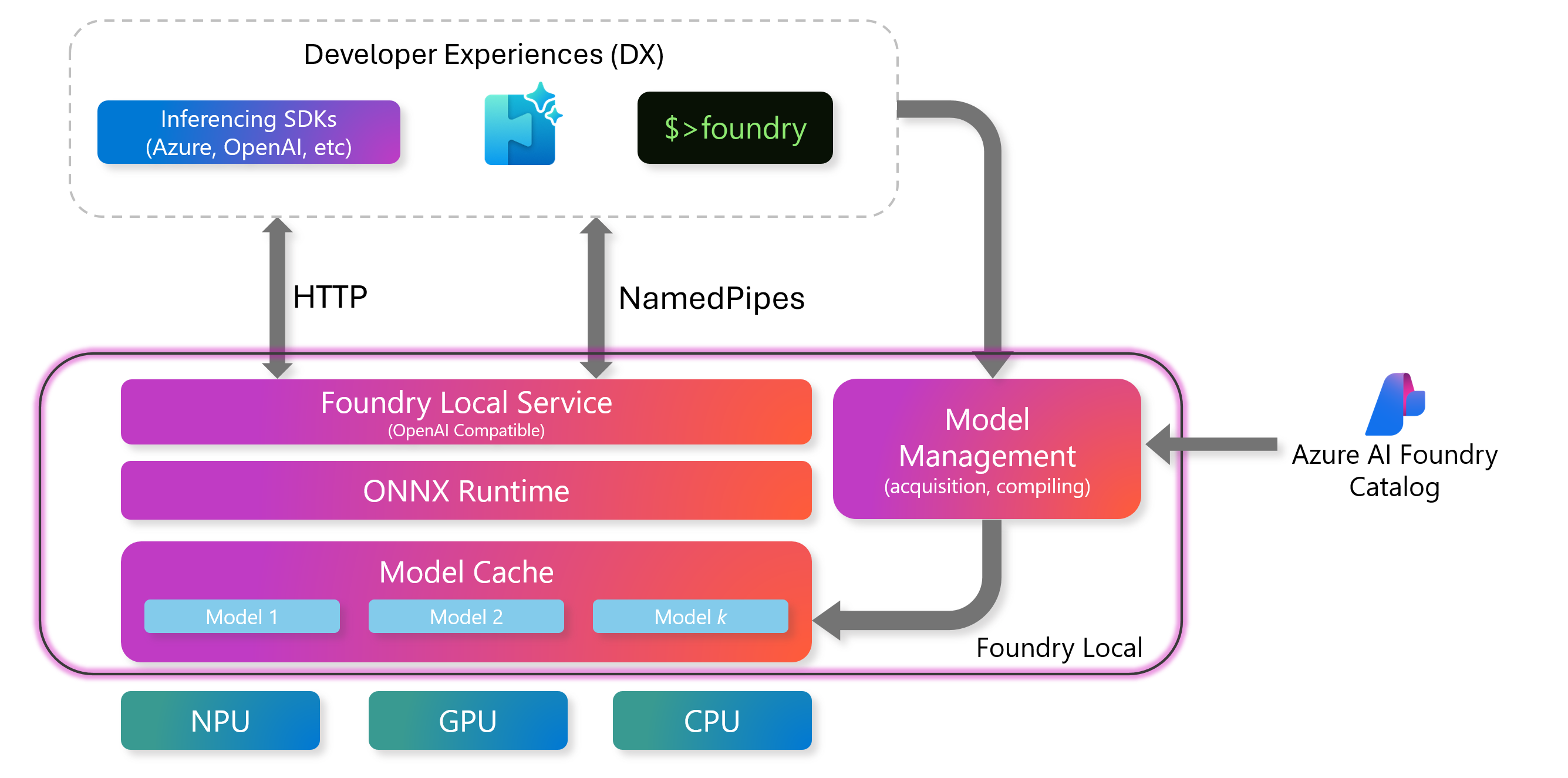
-
Foundry Local 서비스에는 추론 엔진과 상호 작용할 수 있는 표준 인터페이스를 제공하는 OpenAI 호환 REST 서버가 포함
-
REST를 통해 모델을 관리하고, 개발자는 Endpoint API를 활용하여 요청을 보내고, 모델을 실행하며, 결과를 프로그래밍 방식으로 받아올 수 있음
-
엔드포인트:
- 서비스가 시작되면 엔드포인트는 동적으로 할당됨
foundry service status명령어를 실행하면 엔드포인트를 확인할 수 있음- 애플리케이션에서 Foundry Local을 사용할 때는, 엔드포인트를 자동으로 처리해주는 SDK 사용을 권장함
-
활용 사례:
- Foundry Local을 사용자 정의 애플리케이션에 연결
- HTTP 요청을 통해 모델 실행
-
5. ONNX 런타임
- 정의: AI 모델을 실행하는 핵심 구성 요소로, 최적화된 ONNX 모델을 CPU, GPU, NPU와 같은 로컬 하드웨어에서 효율적으로 실행함
- 주요 기능
- NVIDIA, AMD, Intel, Qualcomm 등 다양한 하드웨어 공급업체와 NPU, CPU, GPU 같은 여러 장치 유형을 지원
- 서로 다른 하드웨어에서도 일관된 인터페이스 제공
- 최고 수준의 성능 제공
- 추론 속도를 높이기 위한 양자화(quantized) 모델 지원
6. 모델 관리
-
AI 모델을 효율적으로 관리할 수 있는 강력한 도구들을 제공해, 추론에 사용할 수 있도록 모델을 항상 준비 상태로 유지하고 쉽게 유지 관리할 수 있도록 함.
-
모델 관리는 모델 캐시(Model Cache)와 명령줄 인터페이스(CLI)를 통해 이루어짐.
-
모델 캐시(Model Cache)
-
다운로드된 AI 모델을 로컬 장치에 저장하여, 반복 다운로드 없이 바로 추론에 사용할 수 있도록 함
-
모델 캐시는 Foundry CLI나 REST API를 통해 관리할 수 있음
-
모델을 로컬에 유지함으로써 추론 속도를 향상시킴
-
주요 명령어
명령어 설명 foundry cache list 로컬 캐시에 저장된 모든 모델을 표시함 foundry cache remove 특정 모델을 캐시에서 제거함 foundry cache cd 캐시된 모델의 저장 위치를 변경함
-
7. 모델 생명 주기(Model lifecycle)
- 모델 다운로드 (Download): Azure AI Foundry 모델 카탈로그에서 모델을 다운로드하여 로컬 디스크에 저장함
- 모델 불러오기 (Load):
- 모델을 Foundry Local 서비스 메모리로 불러와 추론에 사용할 수 있도록 함.
- 모델이 메모리에 유지되는 시간을 제어하기 위해 TTL(Time-To-Live)을 설정할 수 있으며, 기본값은 10분임
- 모델 실행 (Run): 요청에 대해 모델 추론을 수행함
- 모델 내리기 (Unload): 더 이상 필요하지 않은 모델을 메모리에서 제거하여 리소스를 확보
- 모델 삭제 (Delete): 로컬 캐시에서 모델을 제거하여 디스크 공간을 회수함
8. Olive를 활용한 모델 컴파일
- Foundry Local에서 모델을 사용하려면 먼저 ONNX 형식으로 컴파일하고 최적화 해야 함
- Azure AI Foundry 모델 카탈로그에 이미 Foundry Local용으로 최적화된 모델들을 일부 제공하고 있으나, Olive를 사용하면 반드시 해당 모델들만 사용할 필요는 없다.
- Olive는 효율적인 추론을 위해 AI 모델을 준비하는 강력한 프레임워크
- 모델을 ONNX 형식으로 변환
- 연산 그래프 구조 최적화
- 로컬 하드웨어 성능 향상을 위한 양자화(Quantization) 등 다양한 최적화 기법 적용
- Olive를 통해 사용자 정의 모델도 Foundry Local에서 사용할 수 있도록 쉽게 준비할 수 있음
9. 하드웨어 추상화 계층(Hardware Abstraction Layer)
- Foundry Local이 다양한 장치에서 실행될 수 있도록 하드웨어를 추상화하여 제공함
- 사용 가능한 하드웨어에 따라 성능을 최적화하기 위해
- NVIDIA CUDA, AMD, Qualcomm, Intel 등 다양한 실행 제공 업체
- CPU, GPU, NPU 등 다양한 장치 유형
- Foundry Local은 특정 하드웨어에 종속되지 않고 폭넓은 환경에서 유연하게 동작할 수 있음
10. 개발자 경험(DX, Developer Experiences)
-
파운드리 개발자 경험
- Foundry Local 아키텍처는 개발자가 AI 모델과 손쉽게 통합하고 상호 작용할 수 있도록 매끄러운 개발 환경을 제공하도록 설계했음
- 개발자는 시스템과 상호 작용하기 위해, 명령줄 인터페이스(CLI), SDK 통합해서 추론하기 및 AI Toolkit for Visual Studio Code 등 다양한 인터페이스를 제공
-
명령 줄 인터페이스(CLI) : Foundry CLI는 모델, 추론 엔진, 로컬 캐시를 관리하기 위한 강력한 도구
명령 설명 foundry model list 로컬 캐시에 있는 사용 가능한 모든 모델을 나열 foundry model run 지정한 모델을 실행함. 캐시에 없으면 다운로드 후 실행되며, 인터랙션이 시작함 foundry service status Foundry 서비스의 상태를 확인함 foundry model –help 모델 관련 명령어와 사용 방법 전체를 표시함 foundry model info 특정 모델에 대한 상세 정보를 표시함 foundry model info --license 특정 모델의 라이선스 정보를 표시함 foundry model download 실행하지 않고 모델만 로컬 캐시에 다운로드함 foundry model load 모델을 Foundry Local 서비스에 로드(메모리에 적재)함 foundry model unload 서비스에서 모델을 언로드(메모리에서 제거)함 -
SDK 통합해서 추론하기
- Foundry Local은 OpenAI SDK와 같은 다양한 언어의 SDK와의 통합을 지원함
- 개발자가 익숙한 프로그래밍 인터페이스를 통해 로컬 추론 엔진과 상호 작용할 수 있도록 함
-
AI Toolkit for Visual Studio Code
- 개발자가 Foundry Local과 손쉽게 상호작용할 수 있도록 도와주는 사용자 친화적인 인터페이스를 제공함
- AI Toolkit for Visual Studio Code을 통해 모델 실행, 로컬 캐시 관리, 결과 시각화를 IDE 내에서 직접 수행할 수 있음
- 주요 기능
- 모델 관리: IDE 내에서 모델을 다운로드, 로드, 실행할 수 있음
- 인터랙티브 콘솔: 요청을 보내고 응답을 실시간으로 확인할 수 있음
- 시각화 도구: 모델 성능 및 결과를 그래픽으로 시각화해 보여줌
댓글남기기