구글, AI Hypercomputer의 추론 업데이트
지난 구글 클라우드 넥스트25에서 소개한 AI Hypercomputer가 이번에는 구글 클라우드 TPU와 더불어 추론에 대해 업데이트를 한 블로그 글이 올라와서 이를 요약해 보았다.
1. AI Hypercomputer를 활용한 추론 워크로드 가속화
- Google Cloud Next 25에서 공개된 AI Hypercomputer의 추론 기능 업데이트 및 Ironwood TPU 발표
- vLLM을 사용한 Trillium TPU 상의 간단하고 고성능의 추론 기능과 GKE의 최신 추론 기능(GKE Inference Gateway 및 GKE Inference Quickstart)과 같은 소프트웨어 결합
- 초저지연 멀티 호스트 분리형 서빙을 위해 Pathways를 통합하는 JetStream, 및 고성능 연산이 요구되는 이미지 생성 워크로드에서 TPU 상에서 뛰어난 성능을 제공하며, 현재까지 출시된 가장 대규모 텍스트-이미지 생성 모델 중 하나인 Flux를 새롭게 지원하는 MaxDiffusion 등 소프트웨어 성능 최적화
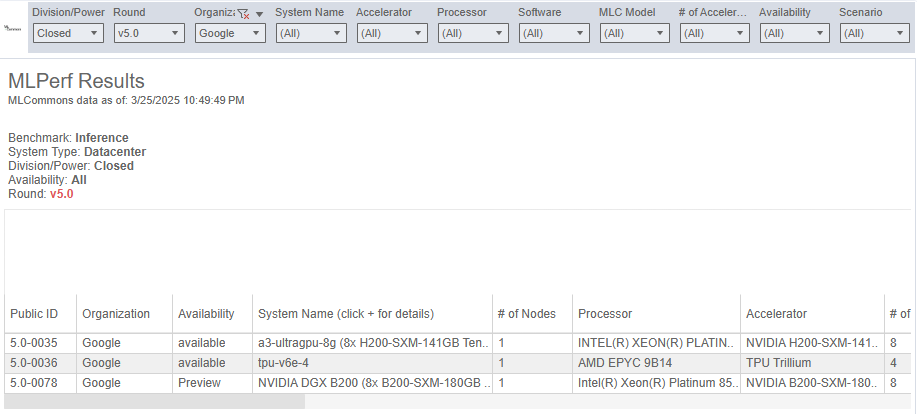
- MLPerf™ Inference v5.0을 통해 Google Cloud의 A3 Ultra (NVIDIA H200) 및 A4 (NVIDIA HGX B200) VM의 강력한 추론 성능 입증
2. JetStream: Google의 JAX 추론 엔진 성능 최적화
- TPU에서 LLM을 제공할 때 더 많은 선택지를 제공하고 JetStream을 개선하여 TPU용 vLLM 지원
- JetStream은 Google의 오픈 소스 추론 엔진으로, Gemini 모델 서빙에 사용하는 동일한 추론 스택을 기반으로 함
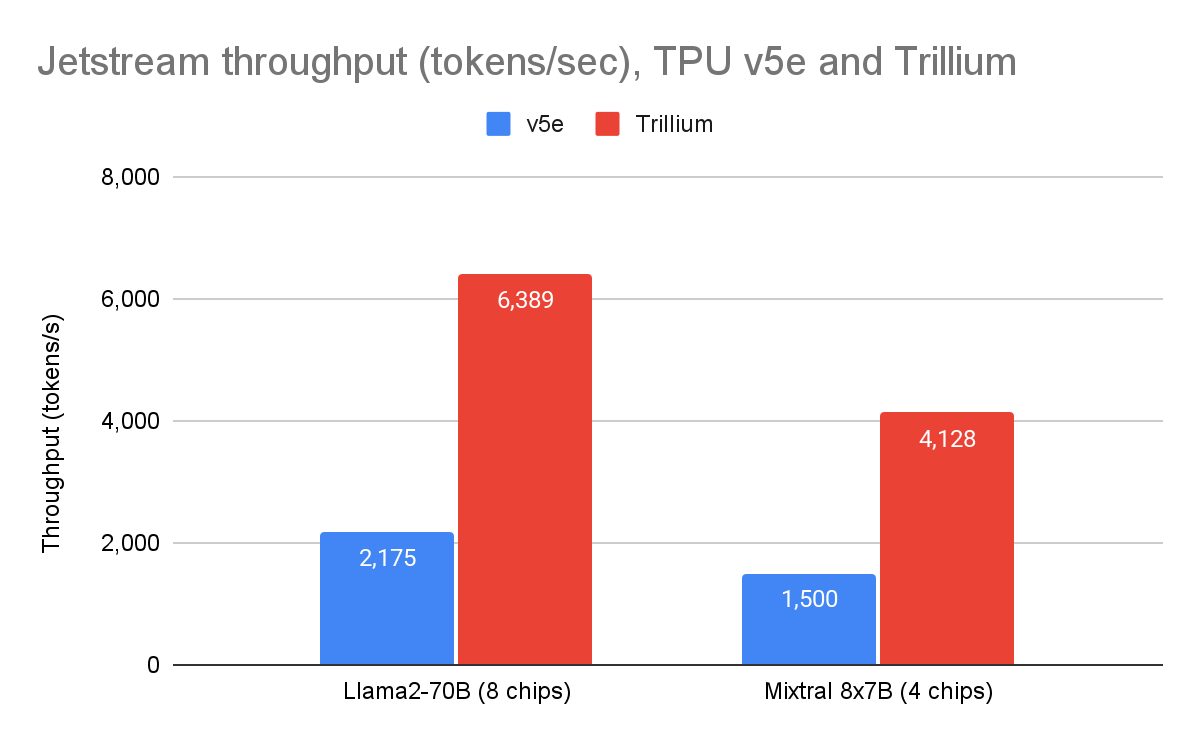
- 6세대 Trillium TPU는 Llama 2 70B 모델에서 TPU v5e 대비 처리량 성능이 2.9배, Mixtral 8x7B 모델에서는 2.8배 향상(기준은 MaxText 레퍼런스 구현 기준).
- JetStream에 하나의 JAX 클라이언트가 수천 개의 TPU 칩에 걸친 여러 개의 대형 TPU 슬라이스를 조율할 수 있게 하여, 대규모 머신러닝 연산을 보다 간단하게 만들어 주는 Pathways 런타임 통합으로 멀티 호스트 추론 및 분리형 서빙 가능
- 모델을 여러 액셀레이터 호스트에 분산시켜 대규모 모델의 추론 가능한 Pathway를 이용한 멀티 호스트 추론
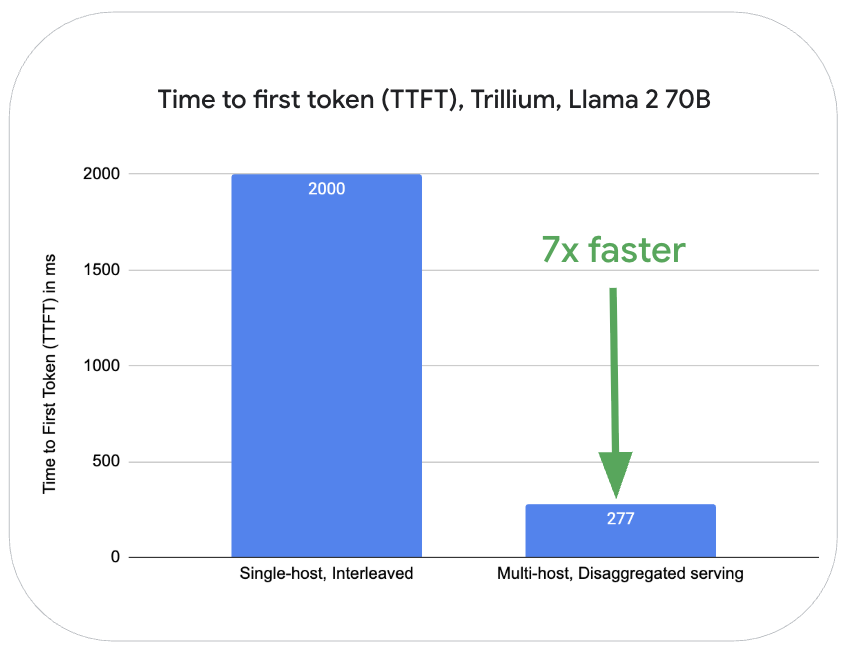
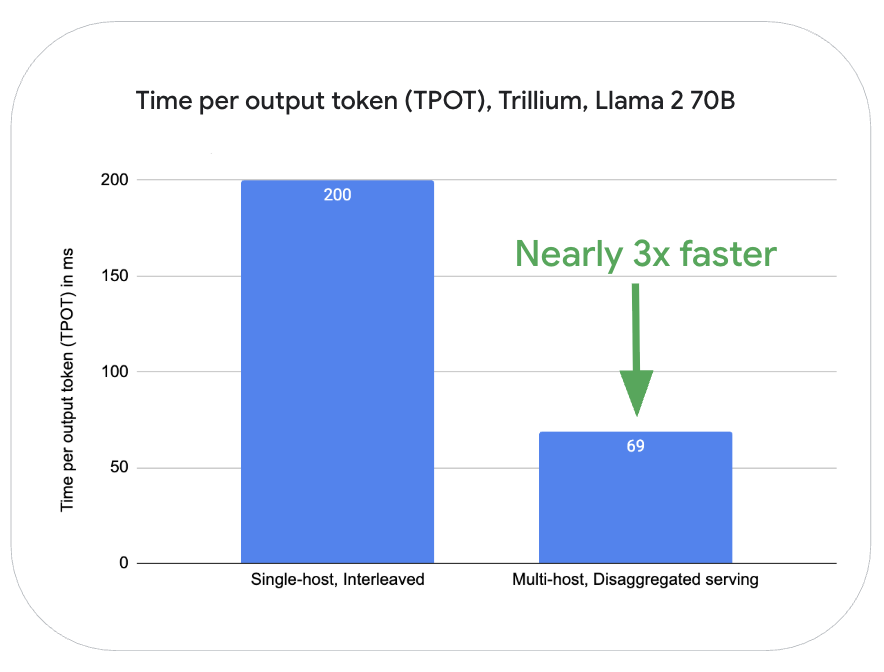
- 분리형 서빙(disaggregated serving): LLM 추론의 디코드 및 프리필 단계를 독립적으로 확장하여 리소스 활용도 향상
- Llama 2-70B 모델의 경우, Trillium TPU 상에서 동일한 서버 내에서 프리필과 디코드 단계를 인터리빙(interleaving) 처리하는 방식과 비교할 때, 여러 호스트를 활용한 분리형 서빙 방식은 프리필(첫 토큰 생성 시간, TTFT) 작업에서 7배, 토큰 생성(출력 토큰당 처리 시간, TPOT)에서는 거의 3배 더 우수한 성능을 보임.
3. 고성능 확산 모델 추론하는 MaxDiffusion
- Trillium은 이미지 생성과 같은 컴퓨팅 집약적인 워크로드에서 뛰어난 성능을 보여줌
- Stable Diffusion 외에도 Flux를 지원하도록 MaxDiffusion 확장
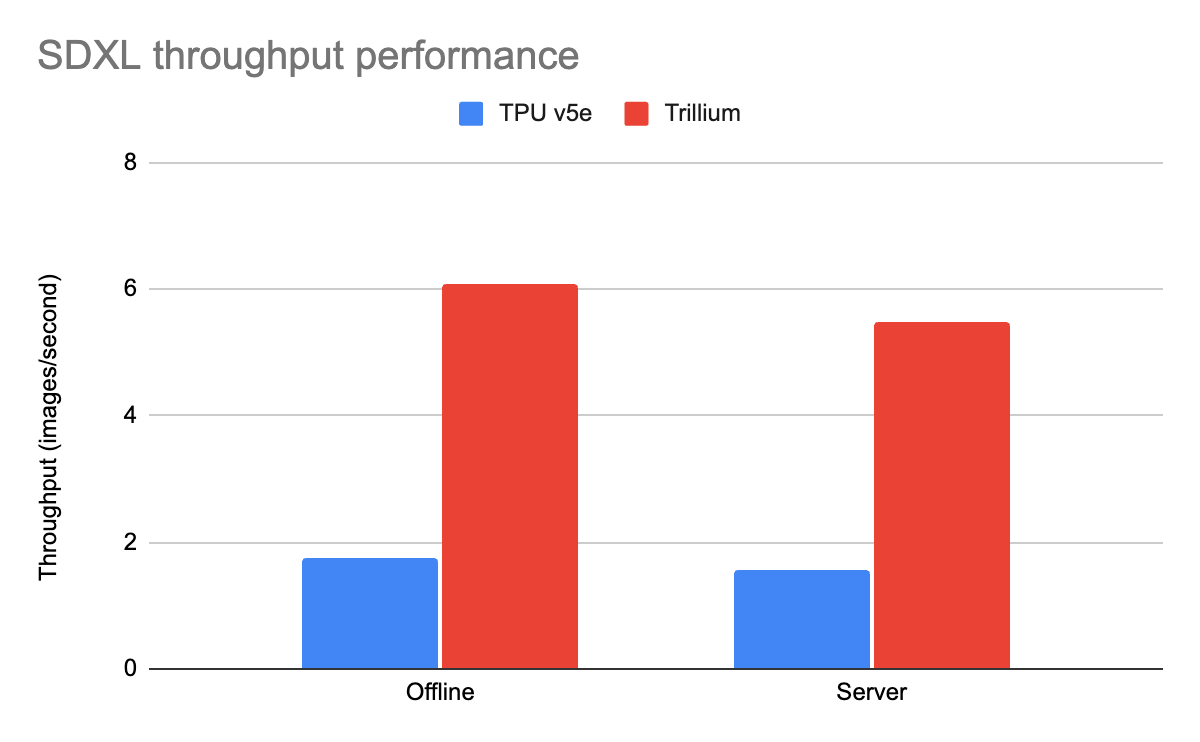
- MLPerf 5.0에서 Trillium은 이전 TPU v5e 대비 SDXL에서 3.5배의 처리량 개선을 제공(MLPerf 4.1 제출 대비 처리량이 추가로 12% 향상)
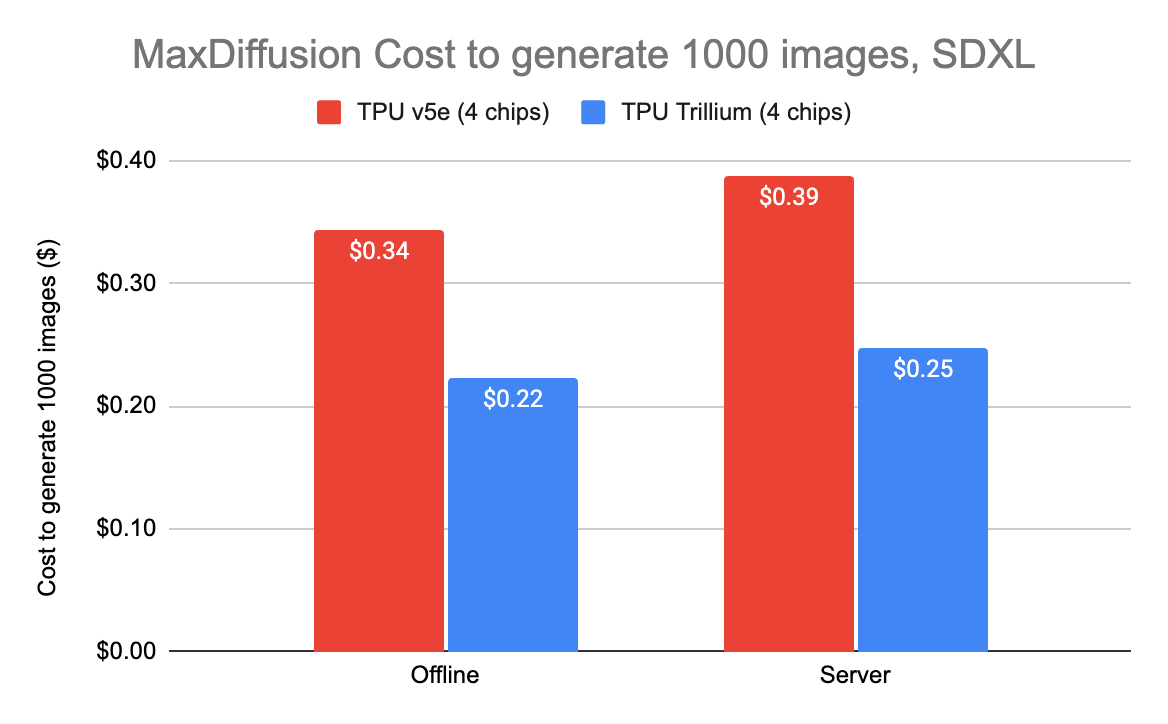
- Trillium에서 1,000장의 이미지를 생성하는 데 드는 비용은 단 22센트로, TPU v5e 대비 35% 저렴
4. A3 Ultra 및 A4 VM MLPerf 5.0 추론 결과
- A3 Ultra (NVIDIA H200) 및 A4 (NVIDIA HGX B200) VM을 사용하여 첫 번째 결과 제출
- A3 Ultra VM은 8개의 NVIDIA H200 Tensor Core GPU로 구동되며, NVIDIA H100 GPU가 탑재된 A3 Mega 대비 2배의 HBM 제공
- Google Cloud는 NVIDIA HGX B200 GPU에서 결과를 제출한 유일한 클라우드 공급업체
5. AI Hypercomputer, AI 추론 시대에 전력 공급
- Google Cloud TPU 및 NVIDIA GPU의 하드웨어 발전과 JetStream, MaxText 및 MaxDiffusion과 같은 소프트웨어 혁신을 통해 AI 혁신 가능
- AI Hypercomputer를 활용하여 추론을 가속화하고, JetStream 및 MaxDiffusion 레시피를 통해 시작 가능
6. 참고
-
구글 클라우드 Compute 블로그 From LLMs to image generation: Accelerate inference workloads with AI Hypercomputer
-
구글 클라우드 하드웨어 블로그: Ironwood: The first Google TPU for the age of inference
-
구글 클라우드 Compute 블로그: Accelerate AI Inference with Google Cloud TPUs and GPUs
-
JetStream 오픈소스: https://github.com/AI-Hypercomputer/JetStream
-
MaxDiffusion 오픈소스: https://github.com/AI-Hypercomputer/maxdiffusion
-
MaxText 오픈소스: https://github.com/AI-Hypercomputer/maxtext
댓글남기기