작년 오픈AI가 GPT-4o 부터 시작해서 Reasoning AI 추론에 대해 선을 보인 후, 많은 연구소와 기업들이 Reasoning AI 추론을 각 모델마다 적용시키고 평가해왔다. 그렇다면, Reasoning AI 추론이란 무엇일까?
1. Reason AI 추론
- 단순히 입력에 대한 빠른 응답을 생성하는 기존 추론(inference)과는 달리, 문제를 ‘생각’하면서 단계적으로 해결하는 고차원 추론 방식
- 높은 품질의 응답과 설명 가능성을 요구하는 프로그래밍, 수학, 법률, 복잡한 질의 응답 등 고부가가치 AI 서비스에 필수적
- AI가 한 번에 답을 내기보다는, 여러 번 생각하며 점진적으로 답을 개선하는 추론 방식
2. Reasoning AI 추론의 주요 특징
| 항목 |
설명 |
| 멀티 패스 추론 (Multi-pass Inference) |
하나의 질문에 대해 여러 번의 추론 과정을 반복하여 점진적으로 정답에 도달 |
| 고차원 사고 (Higher-order Thinking) |
수리 문제, 추론 질문, 복잡한 코딩 작업 등 단계별 사고가 필요한 문제에 적합 |
| 메모리 기반 연산 |
이전 단계에서 생성된 결과나 문맥을 기억하고 다음 단계 추론에 활용 |
| 긴 응답 길이 및 품질 |
생성되는 출력이 길고 정교하며, 설명 가능성과 정확도가 높음 |
| 추론 시 계산량 증가 |
반복적인 reasoning pass와 longer generation으로 인해 Test-time compute가 커짐 |
3. 기존 추론 vs Reasoning 추론
| 시나리오 |
기존 AI 추론 |
Reasoning AI 추론 |
| “3개의 상자에서 사과와 배가 섞여 있다. 조건을 보고 각 상자에 무엇이 들어있는지 맞춰보세요.” |
1회 응답 생성, 정확도 낮음 |
여러 조건을 논리적으로 해석하며 단계별로 추론을 반복해 정확도 높음 |
| 수학 문제 풀이 |
계산 결과만 바로 출력 |
풀이 과정을 단계별로 추론하며 설명까지 제공 |
| LLM으로 코딩 문제 해결 |
바로 코드를 생성 |
조건, 논리 흐름, 에러 가능성을 단계별로 점검하며 코드를 정제해 생성 |
4. 업그레이드된 AI 추론 배포
| 추론 배포 방식 |
설명 |
| 배치 추론 (Batch Inference) |
여러 사용자의 요청을 하나로 묶어 처리하여 GPU 활용률을 극대화하고, 다수 사용자에 대한 고처리량을 제공합니다. |
| 실시간 추론 (Real-Time Inference) |
데이터가 도착하자마자 즉시 처리하며, 자율주행이나 영상 분석처럼 즉각적인 판단이 필요한 애플리케이션에 필수적입니다. |
| 분산 추론 (Distributed) |
여러 장치 또는 노드에서 동시에 추론을 실행하여 계산을 병렬화하고, 대규모 모델의 효율적인 확장과 낮은 지연 시간을 지원합니다. |
| 분리형 추론 (Disaggregated) |
AI 추론 과정을 초기 분석과 응답 생성이라는 두 단계로 분리하여, 각 단계를 전용 컴퓨팅 자원에서 실행함으로써 효율성을 향상시킵니다. |
5. 업그레이드된 LLM 추론 평가
- 최초 토큰 생성 시간 (Time to First Token, TTFT): 사용자 경험
- 정의: 시스템이 첫 번째 토큰을 생성하는 데 걸리는 시간.
- 중요성: 짧은 TTFT는 사용자에게 즉각적인 응답을 제공하여 만족도와 몰입도를 높임
- 예: 챗봇에서 질문을 입력한 후 반응이 빠를수록 사용자 경험이 좋아짐.
- 출력 토큰당 시간 (Time Per Output Token, TPOT): 처리량
- 정의: 이후 각 토큰을 생성하는 데 걸리는 평균 시간.
- 중요성: 전체 응답 속도와 효율성에 직접적인 영향을 미치며, 실시간 챗봇, 통역 서비스 등에서 중요
- 굿풋 (Goodput): 시스템 효율성
- 정의: 목표 TTFT와 TPOT을 유지하면서 얻을 수 있는 실제 처리량(throughput).
- 중요성: 지연 시간, 성능, 비용 간의 균형을 최적화하여 비즈니스 관점에서 AI 추론을 효율적으로 운영하는 데 중요한 지표
6. AI 추론의 도전 과제
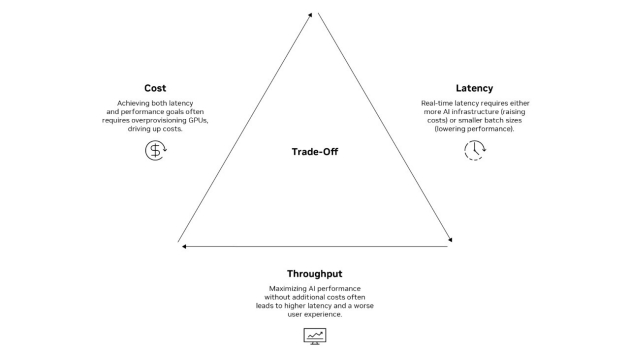
- AI 추론의 핵심 과제는 지연 시간(latency), 비용(cost), 처리량(throughput) 사이의 균형을 맞추는 것
- 높은 성능을 위해 GPU를 과다하게 할당(overprovisioning) 해야 하는 경우가 많아 비용이 증가
- 실시간 추론 요구는 더 많은 AI 인프라 또는 더 작은 배치 크기를 필요로 하며, 이로 인해 처리량이 낮아질 수 있음
- 낮은 지연 시간과 높은 처리량을 동시에 달성하면서도 비용을 절감하는 것은 매우 어려워, 결국 데이터 센터 차원에서의 트레이드오프(절충)가 발생
7. AI 추론 최적화 솔루션
| 기술 (Techniques) |
해결되는 과제 (Challenges Addressed) |
| 고급 배치 처리 (Advanced Batching) |
동적 배치, 시퀀스 배치, 인플라이트 배치 등을 활용해 GPU 사용률을 높이며 처리량과 지연 시간의 균형을 맞춤 |
| 청크 단위 전처리 (Chunked Prefill) |
입력 데이터를 작은 단위로 나누어 처리 시간과 비용을 절감함 |
| 멀티블록 어텐션 (Multiblock Attention) |
어텐션 메커니즘을 최적화하여 중요 입력에만 집중, 계산 부하와 비용을 절감 |
| 모델 앙상블 (Model Ensembles) |
다양한 알고리즘을 조합하여 예측 정확도와 견고성을 향상 |
| 동적 스케일링 (Dynamic Scaling) |
실시간 GPU 리소스 조절로 고성능 유지와 비용 최적화를 동시에 달성, 피크 타임에도 효율적인 대응 가능 |
- 이러한 기술을 도입함으로써 기업은 고성능, 저지연, 비용 효율성을 갖춘 AI 서비스를 제공하고, 사용자 경험과 비즈니스 성과를 극대화함
8. AI 추론형 모델 -> 테스트 타임 스케일링(Test-time scaling)
- AI 추론형(reasoning) 모델은 여러 번의 추론 패스**를 반복 수행하면서 문제를 점진적으로 “생각”
- 더 긴 텍스트 생성 과정과 더 많은 토큰 출력을 통해 더 정교하고 정확한 응답을 만들어냄
- 이를 위해서는 실시간 추론을 지원할 상당한 추론 연산량(test-time compute)이 필요함
9. AI 팩토리에서 AI 추론 역할
- AI 팩토리(AI Factory): AI 모델의 개발, 배포, 지속적인 개선을 자동화하는 대규모 컴퓨팅 인프라를 뜻함
- AI 추론은 훈련된 모델이 실제 환경에서 예측과 판단을 수행하는 마지막 단계
- 클라우드, 하이브리드, 온프레미스 환경에 고성능/저지연 AI 서비스를 제공하는 데 핵심 역할
- AI 팩토리 추론 최적화
- 가속화된 AI 인프라를 지속적으로 관리 및 개선
- AI 데이터 플라이휠(Data Flywheel) 구축: 추론 결과를 다시 학습에 반영하여 모델을 지속적으로 개선
- 이를 통해 AI 시스템은 시간이 지날수록 더 정확하고 효율적인 방향으로 진화
- AI 추론은 AI 팩토리의 핵심 요소로 작동하며, 산업 전반에 걸쳐 확장 가능하고 비용 효율적인 AI 배포를 가능
10. NVIDIA에서 AI 추론 시작하기
- 풀스택 라이브러리, 소프트웨어, 서비스를 모두 제공
- 가장 광범위한 추론 생태계
- 목적에 맞춘 가속화 소프트웨어
- 고성능 네트워킹
- 업계 최고 수준의 전력당 처리 성능(per-watt throughput)
- NVIDIA는 고처리량, 저지연, 비용 효율적인 AI 컴퓨팅을 실현
11. 참고
댓글남기기